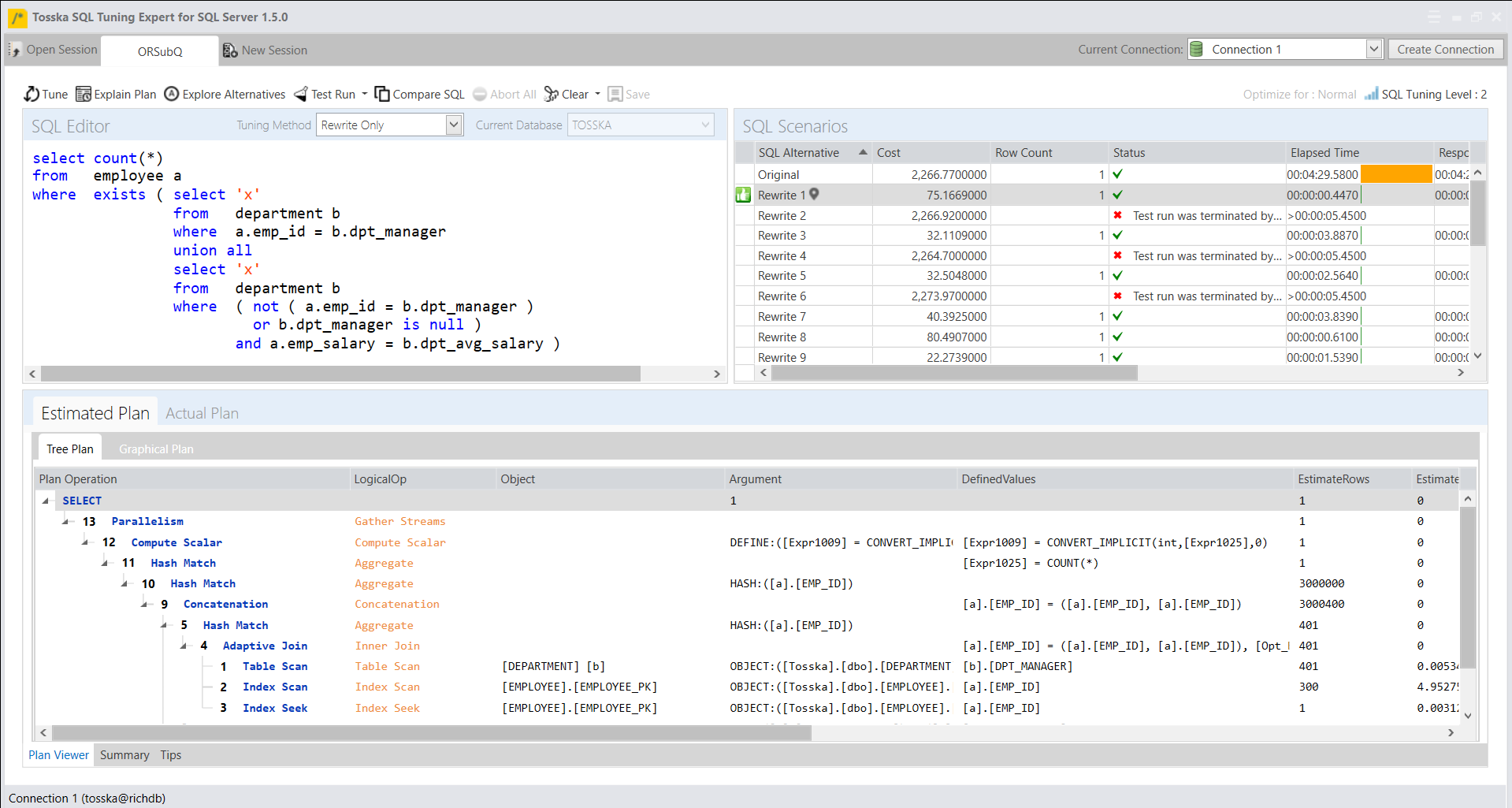
下面示例显示带有EXISTS子查询的SQL语句。如果在DEPARTMENT表的子查询中满足OR条件,SQL会对EMPLOYEE表中的记录进行计数。
select countn(*) from employee a where
exists (select ‘x’ from department b
where a.emp_id=b.dpt_manager or a.emp_salary=b.dpt_avg_salary
)
下面是Tosska专有的树结构执行计划,它需要4分29秒才能完成。
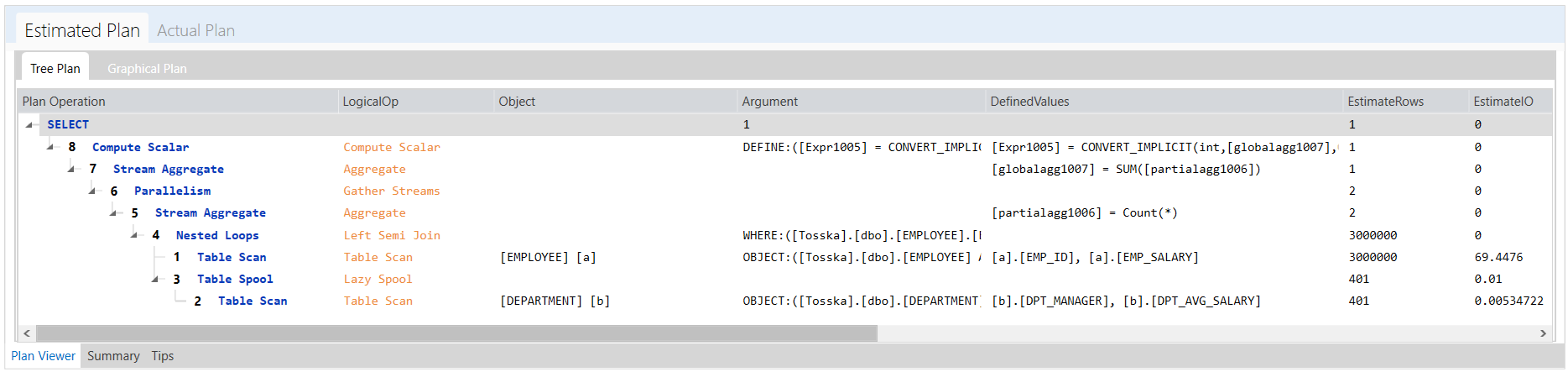
该执行计划显示了从EMPLOYEE到全表扫描DEPARTMENT表的嵌套循环,这是整个执行计划的主要问题。因为 SQL Server 无法通过其他连接操作来解决这个OR条件“a.emp_id=b.dpt_manager or a.emp_salary=b.dpt_avg_salary”。
下面我将子查询中的OR条件改写为UNION ALL子查询,子查询中UNION ALL的第一部分表示“a.emp_id=b.dpt_manager”条件,第二部分表示“a.emp_salary=b.dpt_avg_salary”条件,但排除已经满足第一个条件的数据。
select count(*)
from employee a
where exists ( select ‘x’
from department b
where a.emp_id = b.dpt_manager
union all
select ‘x’
from department b
where ( not ( a.emp_id = b.dpt_manager )
or b.dpt_manager is null )
and a.emp_salary = b.dpt_avg_salary )
下面是改写后SQL的执行计划,看起来有点复杂,但现在性能很好,只需要0.447秒。有两个散列匹配连接用于替换原来从EMPLOYEE表到全表扫描DEPARTMENT表的嵌套循环。
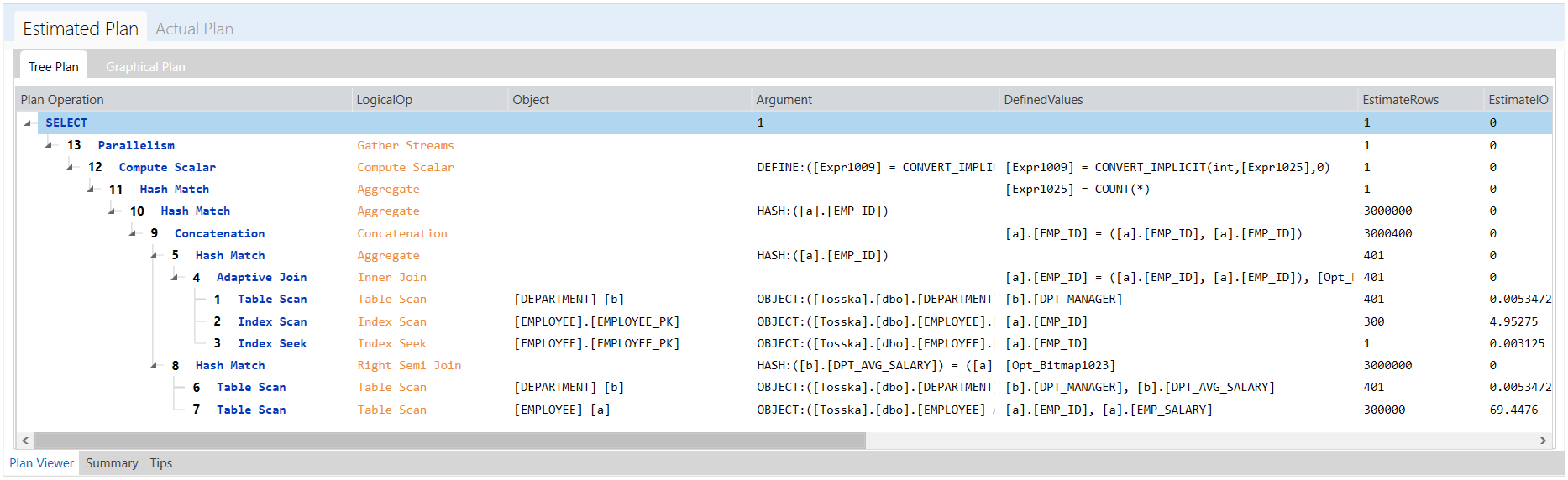
虽然最终改写的步骤有点复杂,但这种改写可以由Tosska SQL Tuning Expert for SQL Server自动完成,这表明该改写SQL比原始SQL快了600多倍。
Tosska SQL Tuning Expert (TSES™) for SQL Server® – Tosska Technologies Limited