
openGauss 是一种开源的关系型数据库管理系统(RDBMS),它起源于 PostgreSQL。openGauss 旨在提供高性能、高可用性和企业级功能。最初由华为开发,后来被开源给社区。openGauss 的 SQL 优化器基于 PostgreSQL,但经过了显著的增强和修改,以提升性能、可扩展性并支持企业级工作负载。虽然官方文档中没有明确说明 openGauss 是从哪个 PostgreSQL 版本继承的初始代码库,但普遍认为 openGauss 起源于 PostgreSQL 9.2.4。因此,当前版本的 openGauss 中可能仍然存在一些来自旧版 PostgreSQL 的遗留 SQL 优化器问题。
在不成熟的 SQL 优化器中,一个常见问题是对 IN 子查询的低效处理。以下是一个带有 IN 子查询的 SQL 语句示例。该查询从 employee 表中检索与 emp_subsidiary 表中 salary 匹配的记录,条件是两者的 emp_id 相同。
select *
from employee a
where a.emp_salary in (select b.emp_salary
from emp_subsidiary b
where a.emp_id = b.emp_id)
以下是查询计划;完成该查询需要 7.2 秒。

查询计划显示了对 employee 表的顺序扫描(sequence scan)和对 emp_subsidiary 表的索引扫描(index scan)。然而,这种查询不适合 employee 与 emp_subsidiary 比例为 30:1 的场景。如果 openGauss 拥有更强大的 SQL 优化器,它应该包含一个内部的 SQL 语法重写机制,将 IN 语句转换为 JOIN 或 EXISTS 语句,从而允许探索更高效的查询计划。>br>
下面,我将使用 EXISTS 语句重写 SQL,如下所示:
select *
from employee a
where exists (select ‘x’
from emp_subsidiary b
where a.emp_salary = b.emp_salary and
a.emp_id = b.emp_id)

重写后的 SQL 仅需 0.34 秒 即可完成,并且在查询计划中使用了 Merge Semi Join——这是一种无法通过原始 IN 语法生成的计划。我们可以看到,重写后的 SQL 成本显著低于原始 SQL 语句。这表明,在 openGauss 对原始查询进行 SQL 优化时,Merge Semi Join 计划并未在其探索的计划空间内。
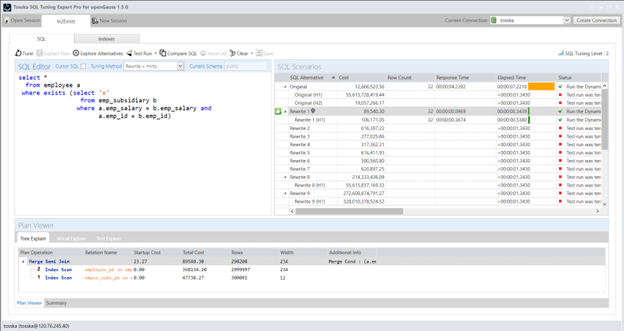
重写后的 SQL 比原始 SQL 快 20 倍以上。这种优化也可以通过使用 Tosska SQL Tuning Expert 在 openGauss 中实现。
Tosska SQL Tuning Expert Pro (TSEG Pro™) for openGauss® – 珠海图思科软件有限公司