以下是一个 SQL 示例,查询从远程数据库 @richdb 检索员工、部门和等级表。
SELECT *
FROM emp_subsidiary@richdb a,
department@richdb,
grade@richdb
WHERE emp_grade < 1200
AND emp_dept = dpt_id
AND emp_grade = grd_id
ORDER BY emp_id
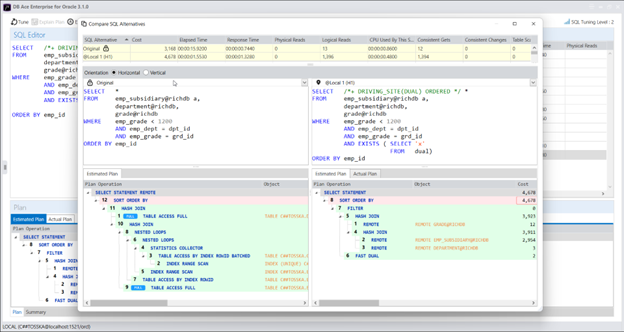
下面是此 SQL 的查询计划,它花费了 15.92 秒才能完成。查询计划的第一步是“SELECT STATEMENT REMOTE”,这意味着整个查询将在远程数据库 @richdb 上执行,并将结果发送回本地数据库。查询计划有点复杂,不容易判断是否最优。但如果查询在本地数据库 @local 上部分执行,我们可以尝试一件事情。
为了请求 Oracle 在本地数据库中执行某些连接操作,SQL 查询必须包含至少一个在本地数据库中执行的表。这才允许在 SQL 查询中使用提示 /*+ DRIVING_SITE ( [ @ queryblock ] tablespec ) */。如果没有表在本地数据库中显式执行,则没有办法请求 Oracle 尝试在本地数据库中执行连接操作。
我们可以在 SQL 中添加一个虚拟条件“EXISTS (SELECT ‘X’ FROM DUAL)”和提示 /*+ DRIVING_SITE(DUAL) */,以强制 Oracle 在本地数据库中执行一些连接操作。
SELECT /*+ DRIVING_SITE(DUAL) */ *
FROM emp_subsidiary@richdb a,
department@richdb,
grade@richdb
WHERE emp_grade < 1200
AND emp_dept = dpt_id
AND emp_grade = grd_id
AND EXISTS ( SELECT ‘x’
FROM dual)
ORDER BY emp_id
以下是修改后的 SQL 的查询计划,它花费了 4.08 秒,比原始 SQL 语句快约 4 倍,其中仅有一个连接操作在远程数据库中执行。

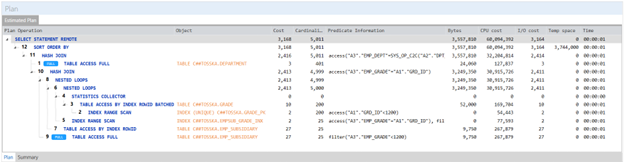
在 SQL 查询中添加 ORDERED 提示可以进一步优化查询。这将会将在上一个查询计划中标记的复合语句分解为单个表数据的远程提取,如下面的查询计划所示。
SELECT /*+ DRIVING_SITE(DUAL) ORDERED */ *
FROM emp_subsidiary@richdb a,
department@richdb,
grade@richdb
WHERE emp_grade < 1200
AND emp_dept = dpt_id
AND emp_grade = grd_id
AND EXISTS ( SELECT ‘x’
FROM dual)
ORDER BY emp_id

如果您熟悉 Oracle Exadata,您可能会注意到远程数据库 @richdb 中 REMOTE 表的数据检索过程,类似于 Exadata 存储服务器的工作方式。
需要记住的是,将此技术应用于具有 DB Link 的 SQL 查询只在某些环境下有益。例如,当网络速度良好、数据流量不大且本地数据库的工作负载较低时,这种技术是理想的。
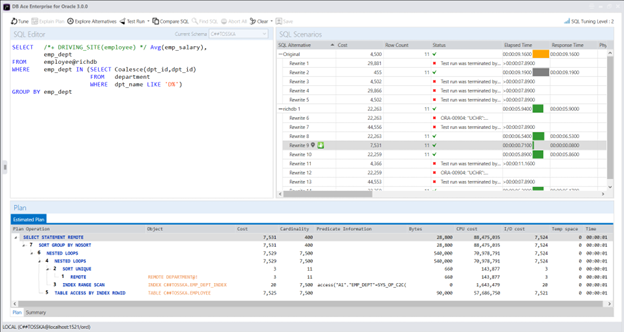
Tosska DB Ace for Oracle 可以自动执行此类重写,从而生成一个比原始 SQL 查询快近 10 倍的 SQL 查询。
Tosska DB Ace Enterprise for Oracle – Tosska Technologies Limited
DBAO Tune DB Link SQL – YouTube