常见的SQL调优方法
SQL 调优是提高 SQL 语句性能,达到用户期望的过程。开发人员或 DBA 通常使用三种方法,这些方法包括创建新索引、重写 SQL 语句和将 Oracle 优化器提示应用于 SQL 语句。每种方法都有其优缺点,适用于应用周期的不同阶段。让我们在下面讨论这三种方法。
为SQL语句创建新的索引
为SQL语句创建新的索引是提高SQL性能的一种非常常见的方法,在数据库开发过程中尤其重要。由于SQL语句的新索引不仅影响当前SQL,还影响同一数据库上运行的其他SQL语句。因此,在生产数据库中应谨慎使用。通常,用户需要对新创建的索引的其他相关SQL语句进行影响分析。
重写 SQL 语句
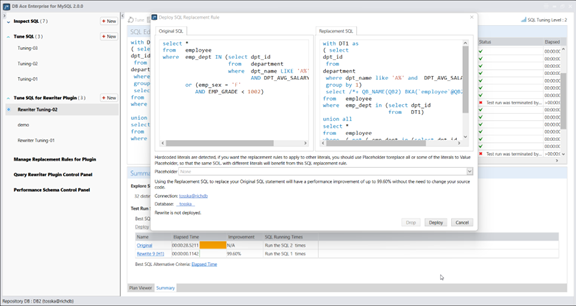
有很多人通过互联网教授 SQL 重写技能。这些重写规则大多都基于 Oracle 规则的 SQL 优化器或基于成本的 SQL 优化器的旧版本继承。例如,有些人可能认为以下 SQL 可能具有不同的性能:
Select * from A where A.unique_key in (select B.unique_key from B);
Select * from A where exists (select ‘x’ from B where A.unique_key=B.unique_key);
实际上,如果将这两个 SQL 放入 Oracle 数据库中,您可能会从 Oracle 获得相同的查询计划;这是因为 Oracle SQL 优化器将在内部将这两个 SQL 重写为一个标准形式,以便生成更好的查询计划。在过去的二十年中,Oracle SQL optimizer开发了一种更强大的内部重写能力。因此,Oracle已经解决了一些明显的问题,如“KEY IS NOT NULL”或“NVL(KEY, ‘ ABC ‘) = ‘ ABC ‘”不能使用索引。当然,对于复杂的SQL转换,Oracle SQL optimizer仍然存在一些限制,因此经验丰富的用户仍然可以通过SQL重写来调优SQL语句,从而影响Oracle SQL optimizer生成更好的查询计划。但是,由于 SQL 语法和最终查询计划生成之间的关系越来越弱,因此 DBA 越来越难以应用此方法,这是因为Oracle基于成本的优化器(CBO) 变得越来越智能,并且 SQL 文本的语法不再是成本计算和计划生成中的主导因素。
SQL 重写在开发和生产数据库中仍然很有用,因为它是对数据库的单独更改,并且不会影响其他 SQL 的性能,并且比创建新索引更安全。但是它需要在程序源代码中修改SQL语句,因此单元测试或集成测试可能仍是必需的。相反,使用提示来调整 SQL 相对更安全,因为不容易意外地更改SQL的语义。
对SQL语句应用提示
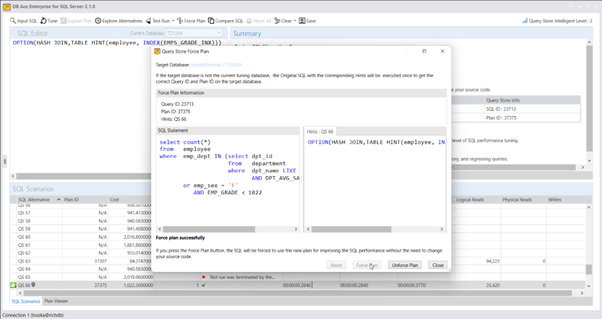
市场上的大多数数据库都提供了一些查询计划控制语言,以帮助其优化器更好地优化特定的 SQL 语句。例如:IBM LUW 优化指南和 SQL Server 计划指南已经提供了多年。Oracle 提供了嵌入 SQL 文本的优化器提示,用于告诉 Oracle SQL 优化器如何优化 SQL 语句。由于提示不会影响 SQL 语句的语义,因此它比 SQL 重写和生成新索引相对更安全。Oracle提供了超过100个文档化的优化提示。使用正确的提示来调整 SQL 是并不容易掌握,除非您是使用优化器提示的专家,即使是专家,如果从一百个提示中挑选只3个提示,那也是非常的困难的, 因为它是接近一百万的排列。
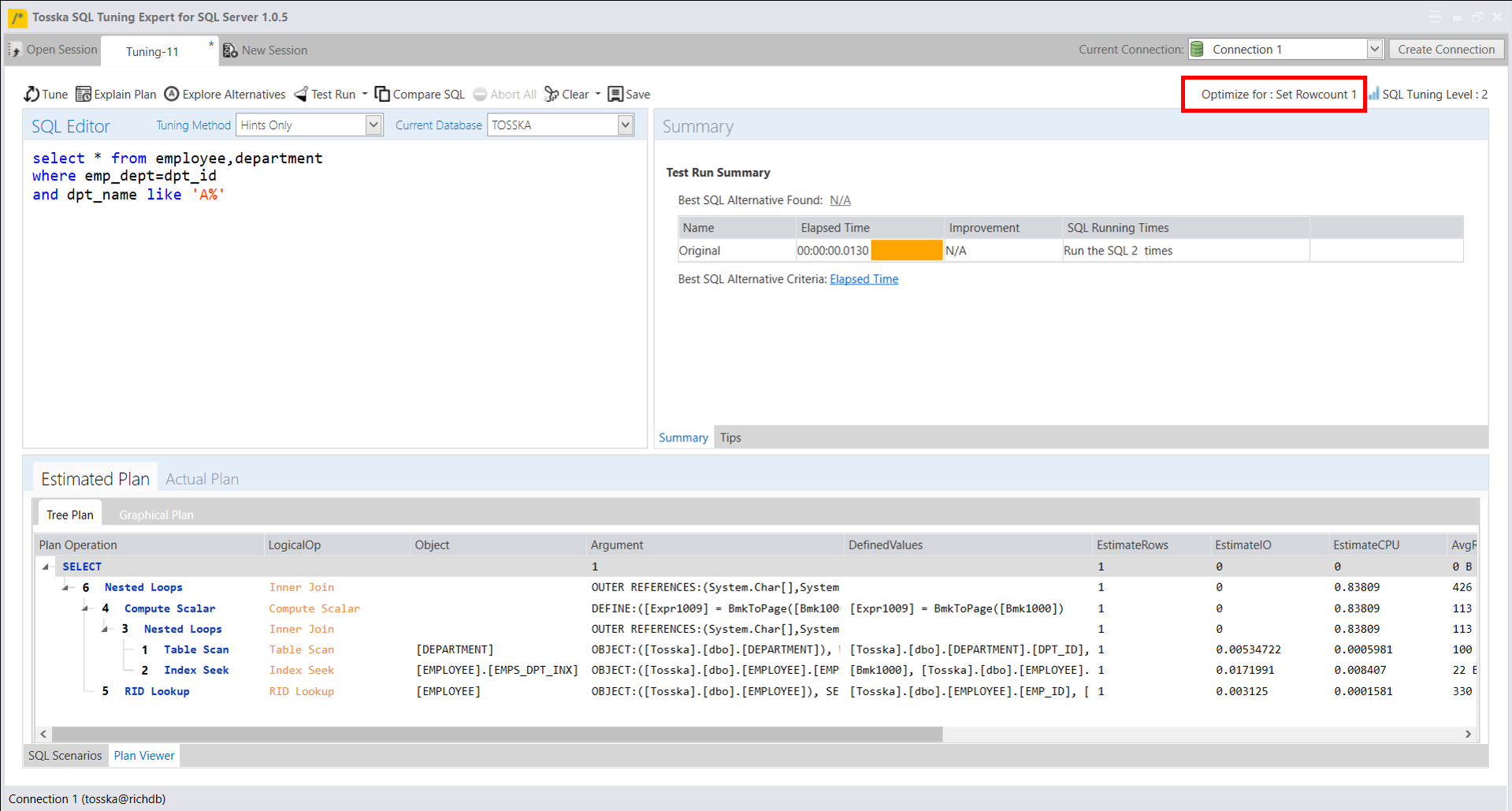
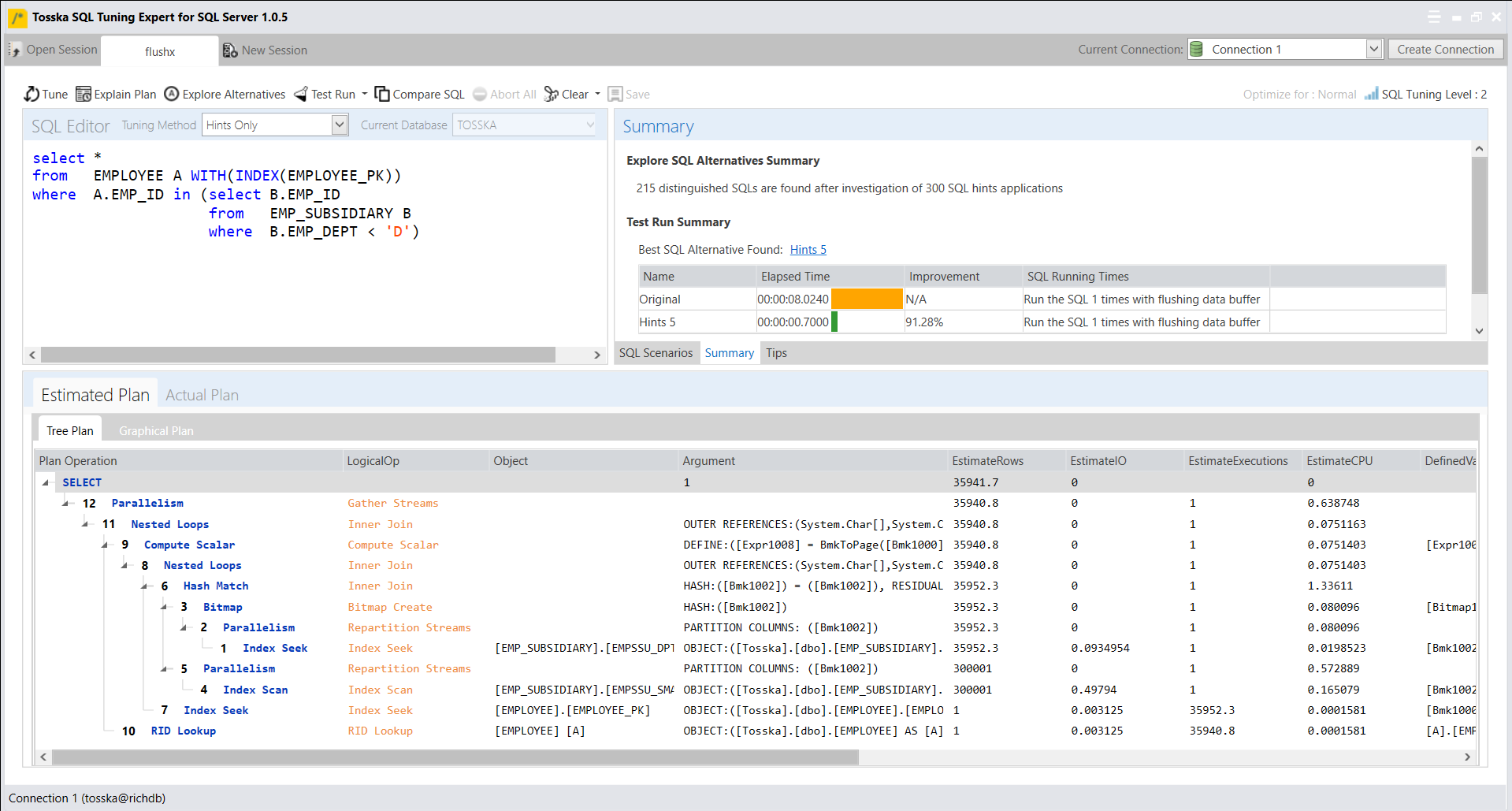
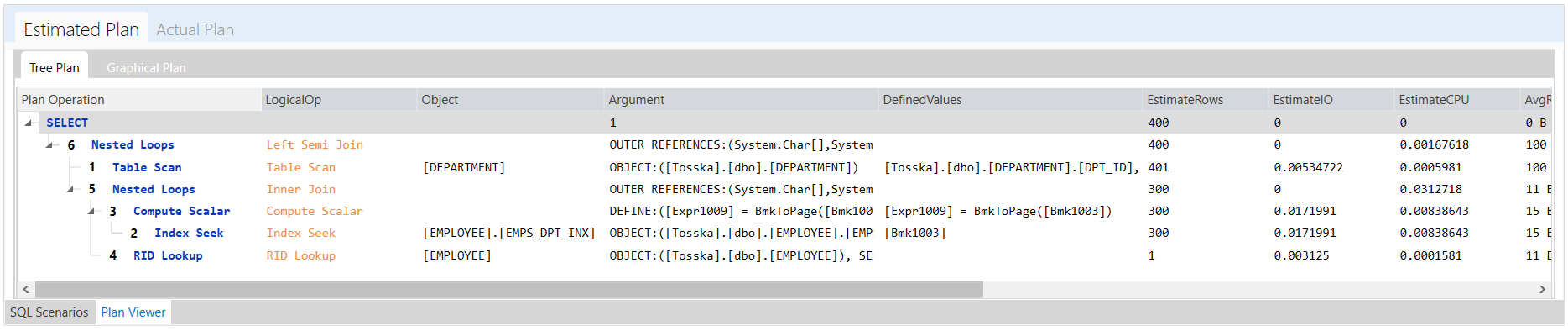
让我们用一个带有以下 Optimizer Hints 的简单SQL示例来展示优化提示是如何工作的,这些提示用于告诉Oracle SQL Optimizer在查询计划选择期间尽可能使用DEPARTMENT表的索引。Oracle将通过对DEPARTMENT表的索引检索,在所有计划中寻找成本最低的计划。
Select /*+ INDEX(@QB2 DEPARTMENT) */ *
From employee
Where emp_dept in (Select /*+ QB_NAME(QB2) */ dpt_id
From department
Where dpt_name LIKE ‘D%’);
Oracle SQL提示不是一种编程语言
Oracle Optimizer hint不是一种带有正确语法检查或错误返回的编程语言。这意味着一个无效的SQL语句提示指令,Oracle SQL优化器不会返回错误消息。此外,即使这是一条有效的提示指令,Oracle SQL优化器实际上不能遵守,也不会返回错误消息。因此,在影响SQL优化器生成特定的更好的查询计划之前,用户必须进行大量的反复试验。
了解解决方案
这是一个非常常见的调优实践,人们试图为性能较差的SQL语句找到最佳的查询计划,它的工作就像一个人模拟Oracle SQL优化器的工作,用人的知识优化SQL语句。如果SQL语句很简单,而且Oracle SQL优化器犯了一个明显的错误,那么人工干预对这种简单的SQL很有效。举个例子:
Select * from A where A.KEY<’ABC’;
如果Oracle SQL optimizer没有使用索引从表A检索记录,而使用索引KEY1实际上是一个更好的解决方案。您可以使用优化器提示来指示Oracle对该SQL语句使用索引而不是全表扫描。
Select /*+ INDEX(KEY1 KEY1_INX) */ from A where A.KEY1<’ABC’ and A.KEY2<123 and A.KEY3<’C’;
了解最佳解决方案对于简单的 SQL 语句来说很容易,但对于复杂的 SQL 语句来说却很难。由于复杂 SQL 的查询计划中有很多执行步骤,因此人类无法估计每个步骤并制定一系列查询步骤来组成最佳性能查询计划。因此,使用 Oracle 优化器提示来指示 SQL 优化器为复杂 SQL 生成特定的查询计划可能并不容易,即使对于经验丰富的 SQL 调优专家也是如此。
了解问题
与了解 SQL 语句的解决方案不同,人工专家可以相对更轻松地查找问题在复杂查询计划中的位置。告诉 Oracle 绕过此问题的方法是应用前缀为”NO_”的提示,如 NO_INDEX 或 NO_USE_HASH。它告诉 Oracle 不要在查询计划中使用指定的操作,而是选择成本较低的其他操作。这种方法在市场上并不普遍采用,因为人们通常受以解决方案为导向的思维的约束。
例如:
Select /*+ NO_INDEX(KEY2 KEY2_INX) */ * from A where A.KEY1<’ABC’ and A.KEY2<123 and A.KEY3<’C’;
如果您认为 KEY2_INX 不是从表 A 检索记录的好索引,则可以通过应用 /* NO_INDEX(KEY2 KEY2_INX)*/ 来禁用 KEY2 索引,并让 Oracle 选择其他索引来检索记录。
释放Oracle优化器提示的潜在功能
无论您是使用面向解决方案的方法还是问题绕过方法,您都需要了解 SQL 查询计划的详细信息、数据分布、每个步骤的成本,并尝试预测计划的最终实际聚合成本是什么。有时,您必须将这两种技术用于复杂的 SQL 语句;您必须为查询计划的某些部分提供最佳查询步骤,并使用”NO_”绕过查询计划中的已知问题。这是一个非常复杂的过程,如果没有对 SQL 调优的深入了解,普通 SQL 开发人员很难执行。
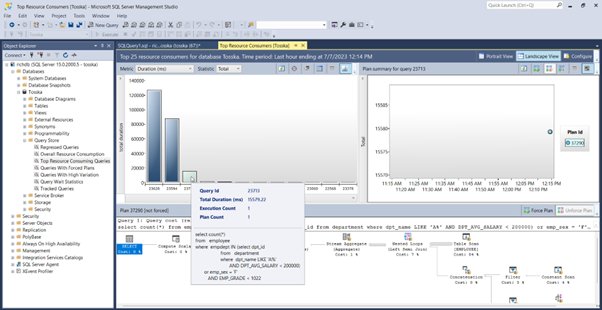
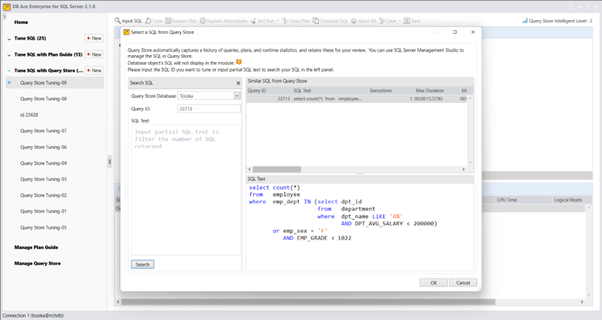
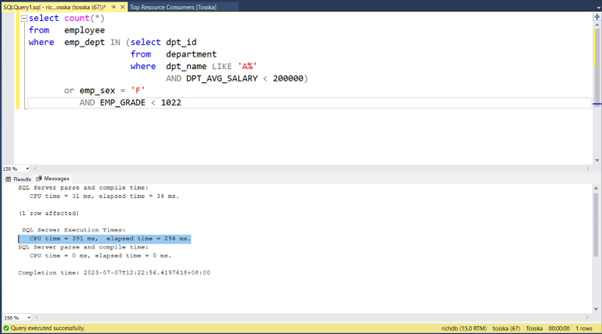
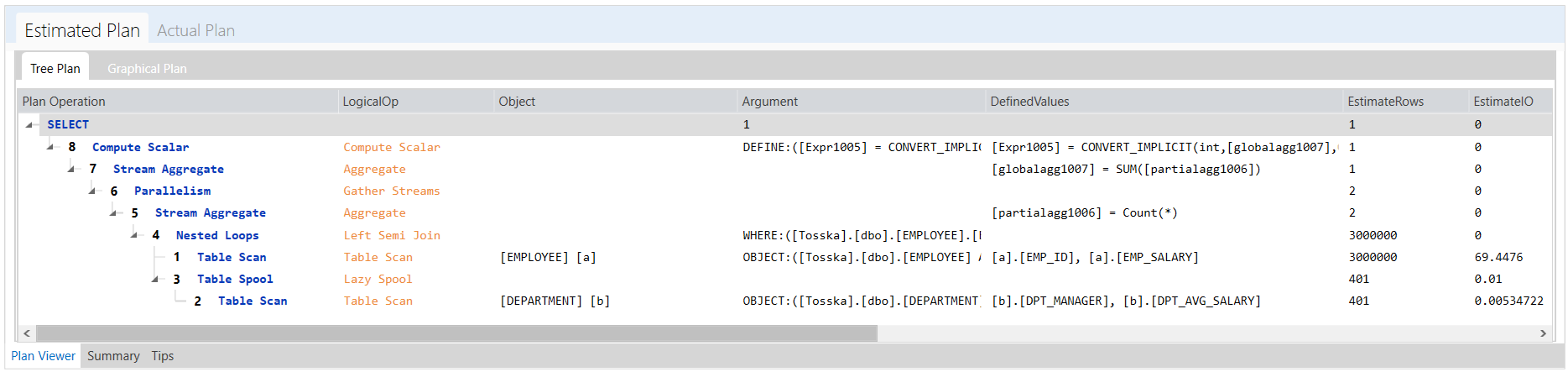
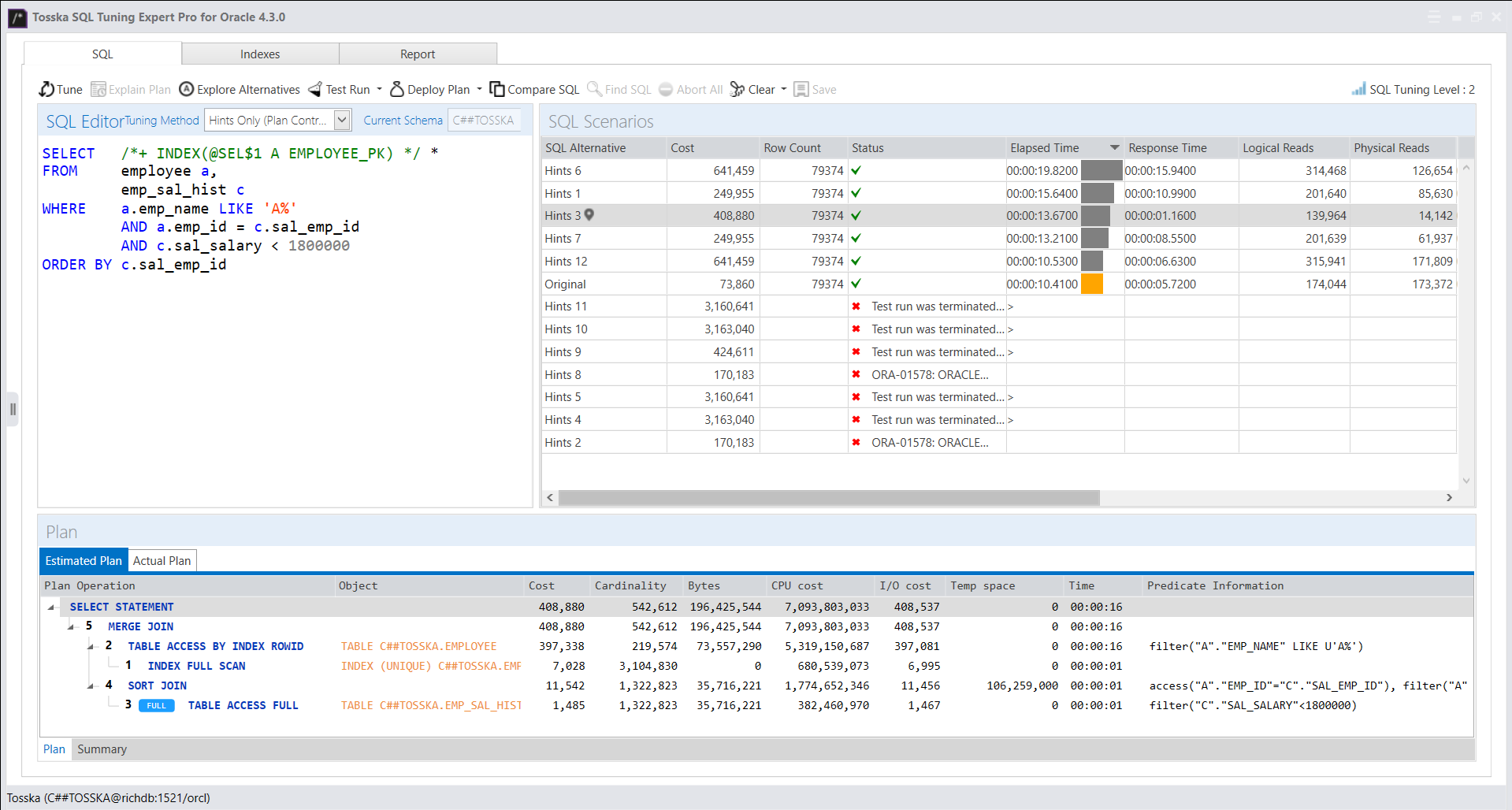
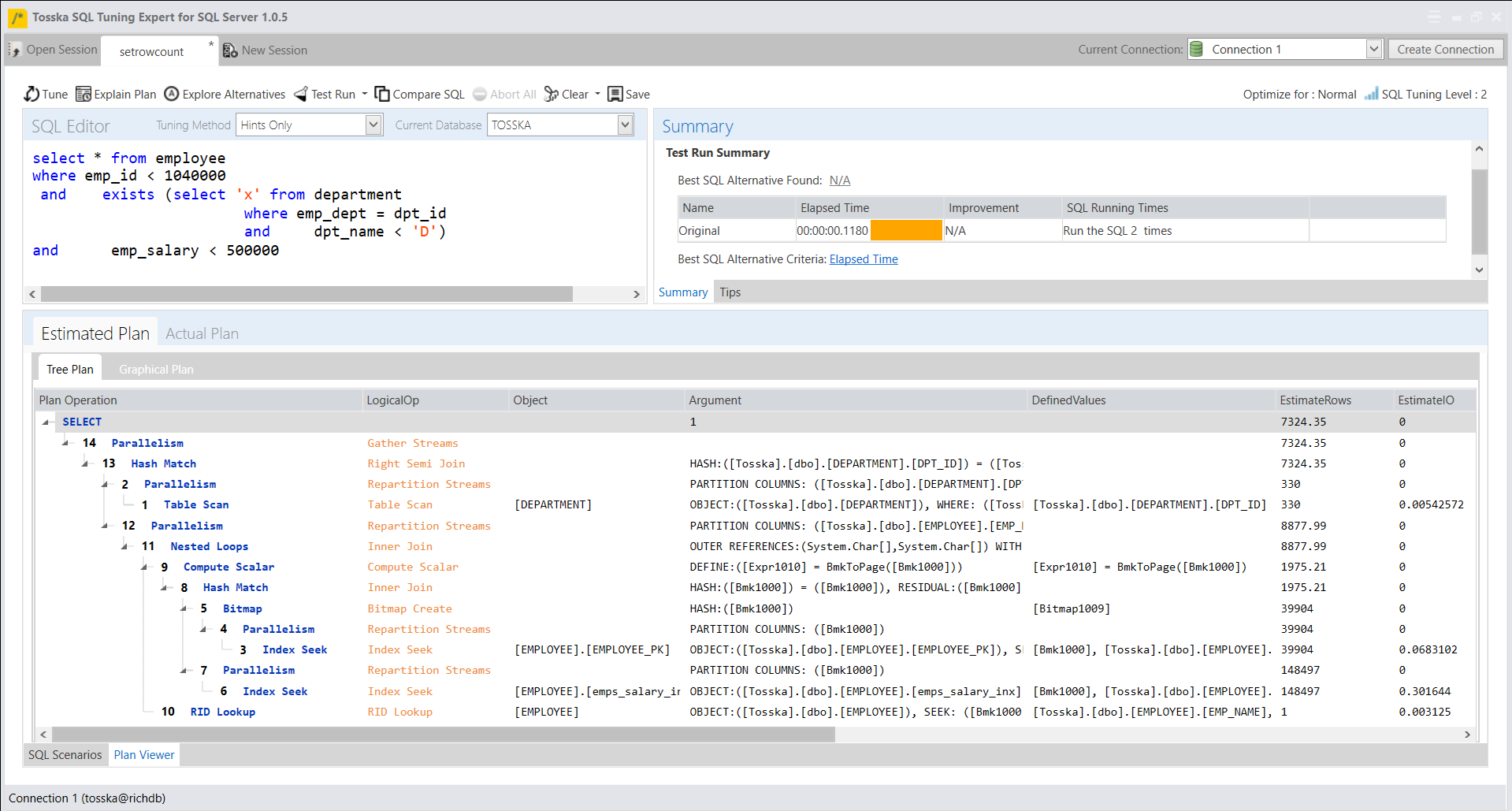
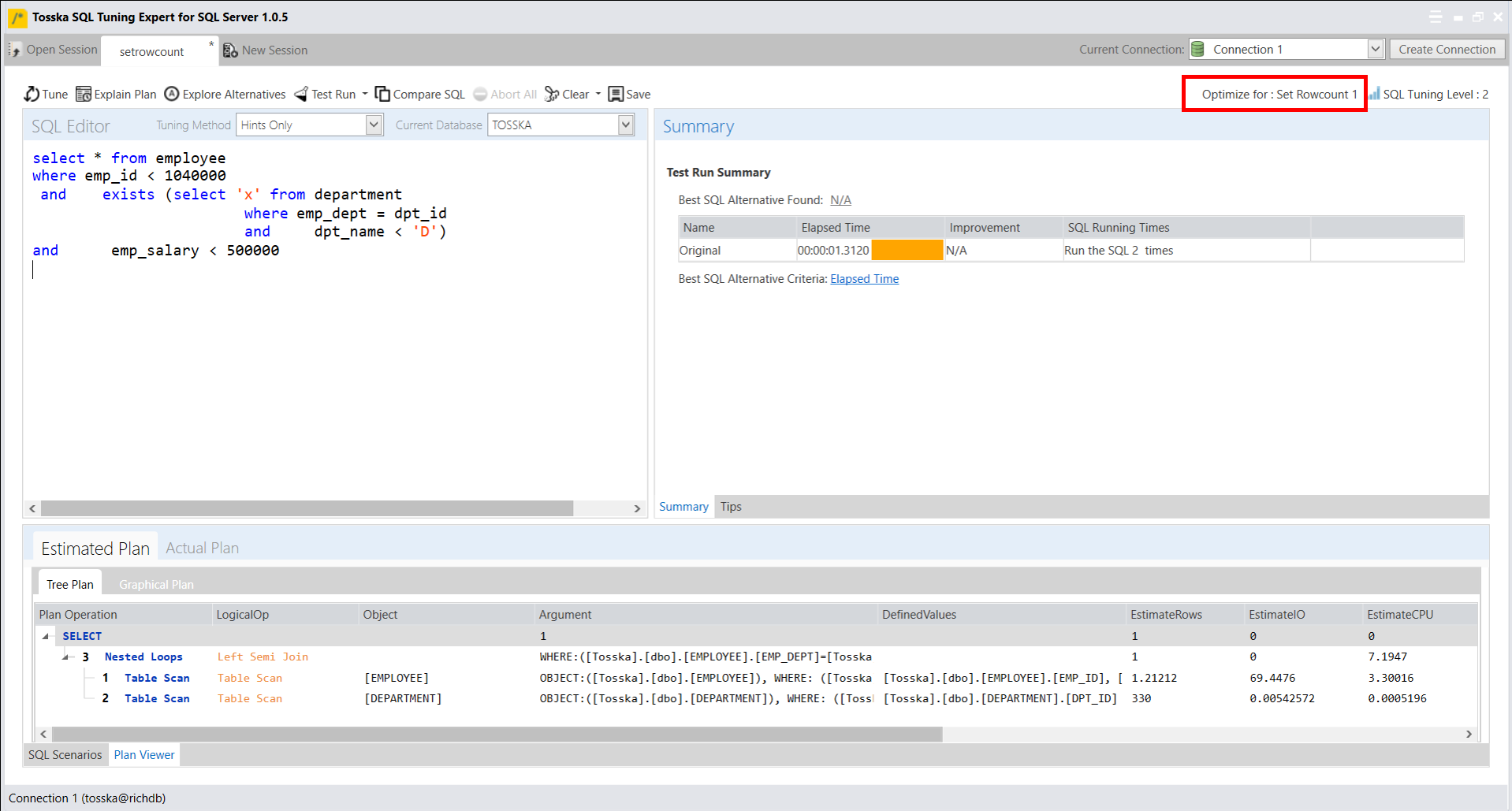
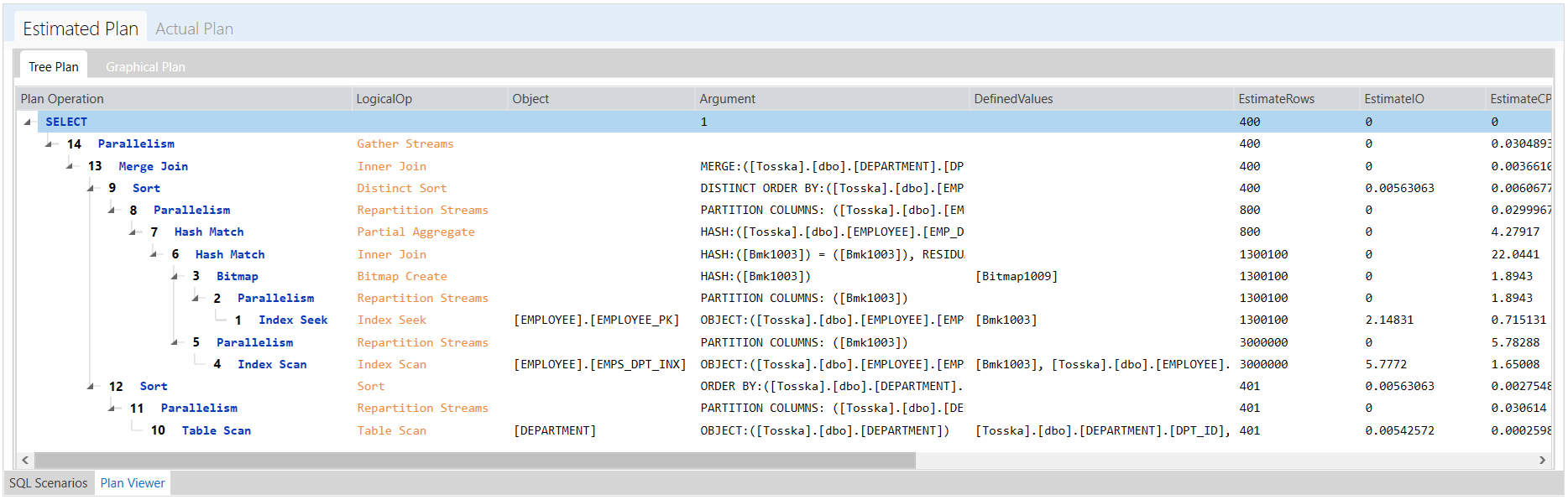
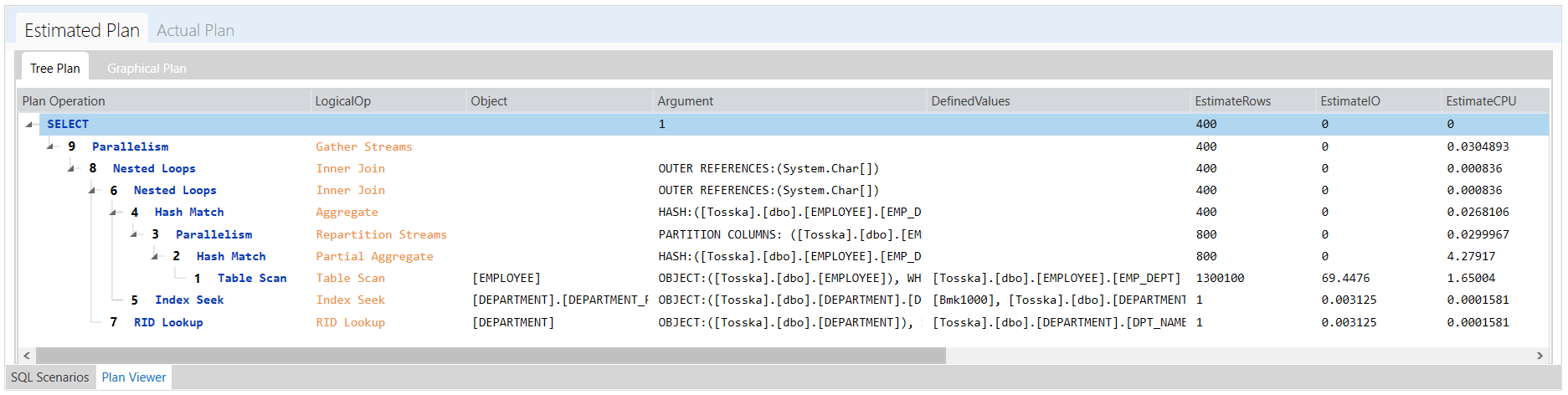
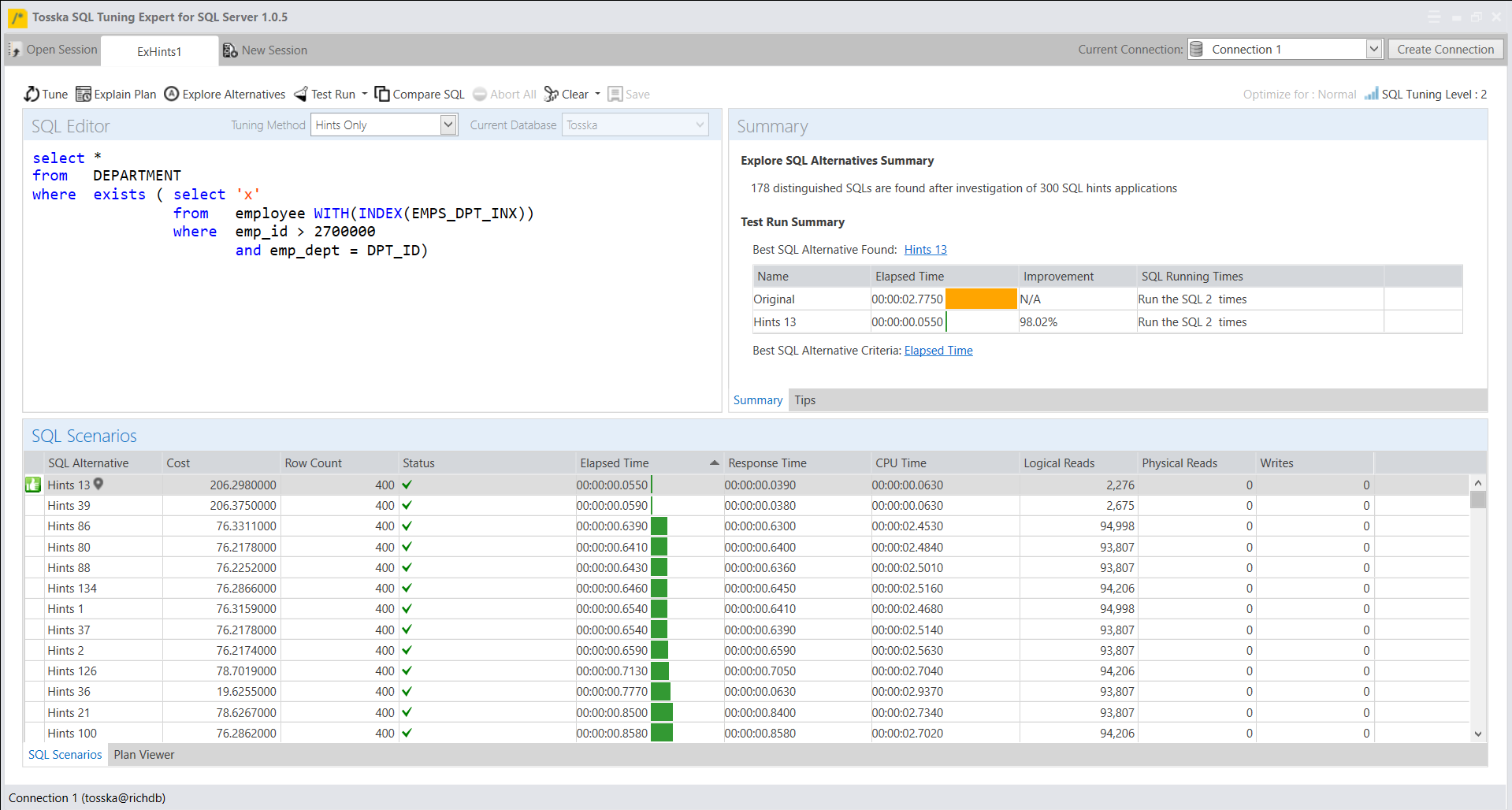
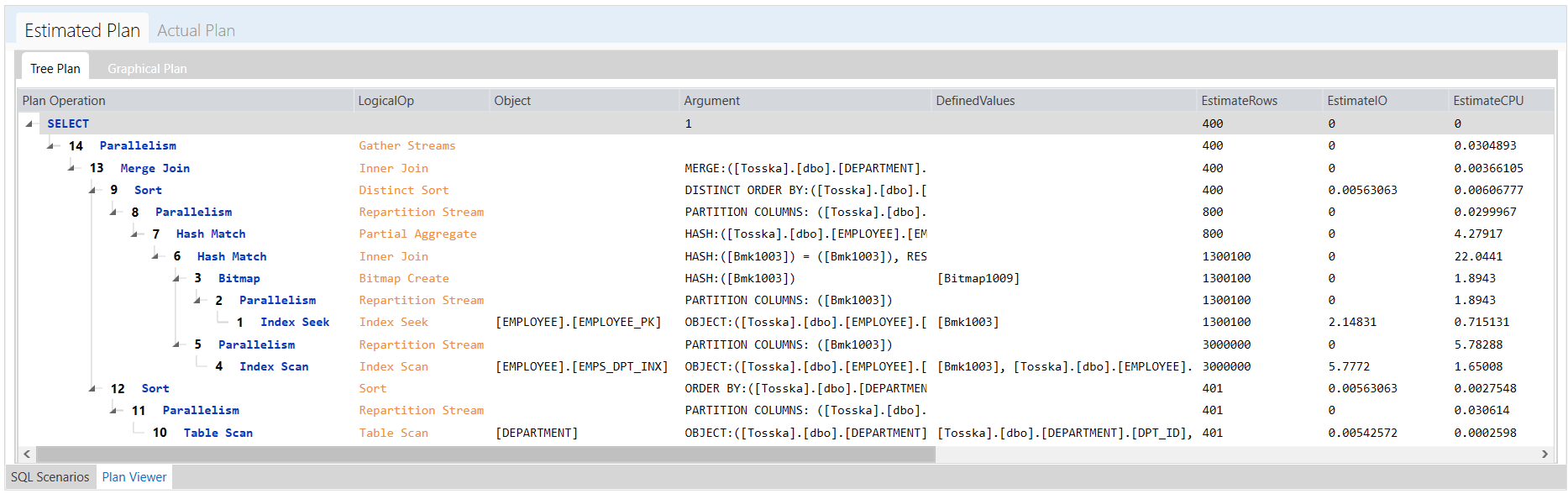
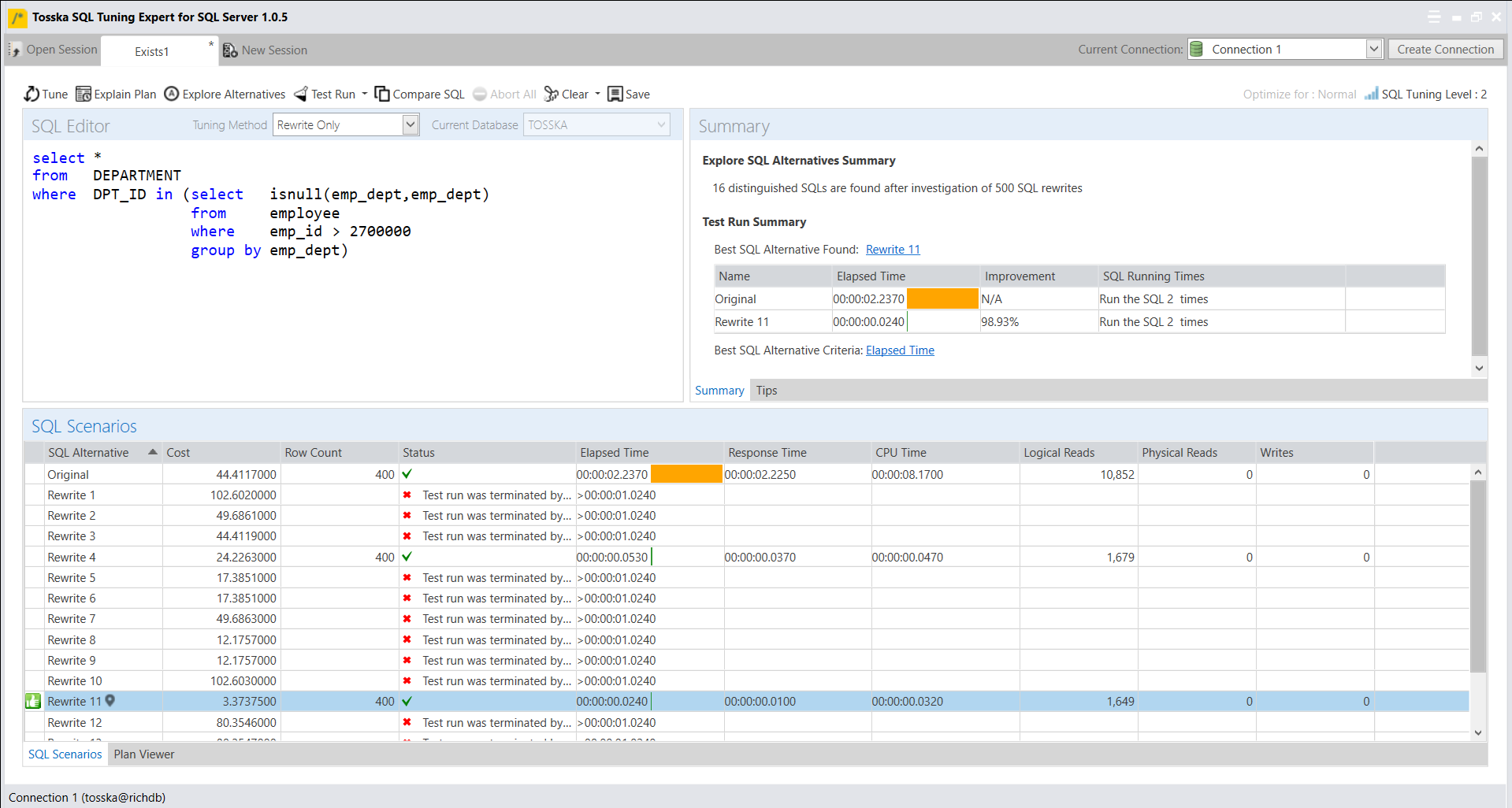
下面的示例显示了一个花费8.56秒完成的SQL,查询计划看起来很正常。SQL语法是完整的,因此没有太多空间进行SQL重写。可能并行执行可以帮助改进SQL语句,但是应该使用哪个表或索引进行并行执行,以及新的并行执行步骤如何影响整个查询计划。即使对于经验丰富的 SQL 调优专家来说,这也不是一件容易的事。这就是为什么Oracle优化器提示没有从一开始就被充分挖掘的原因。
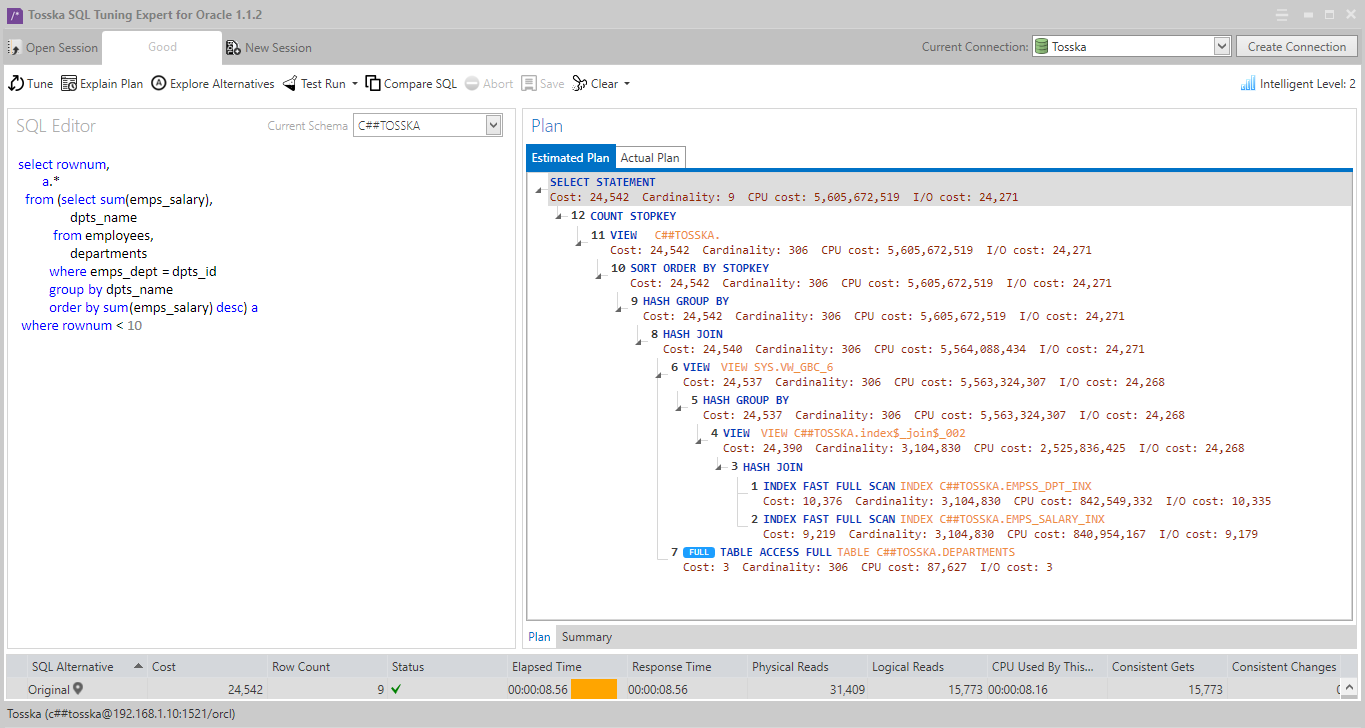
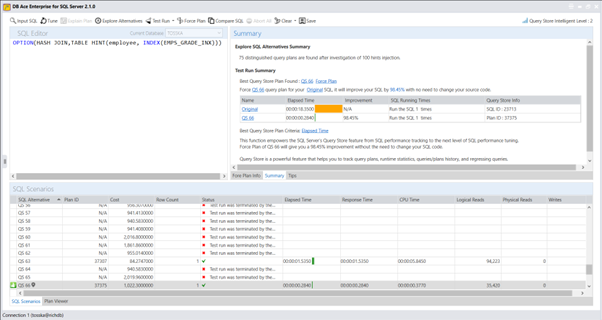
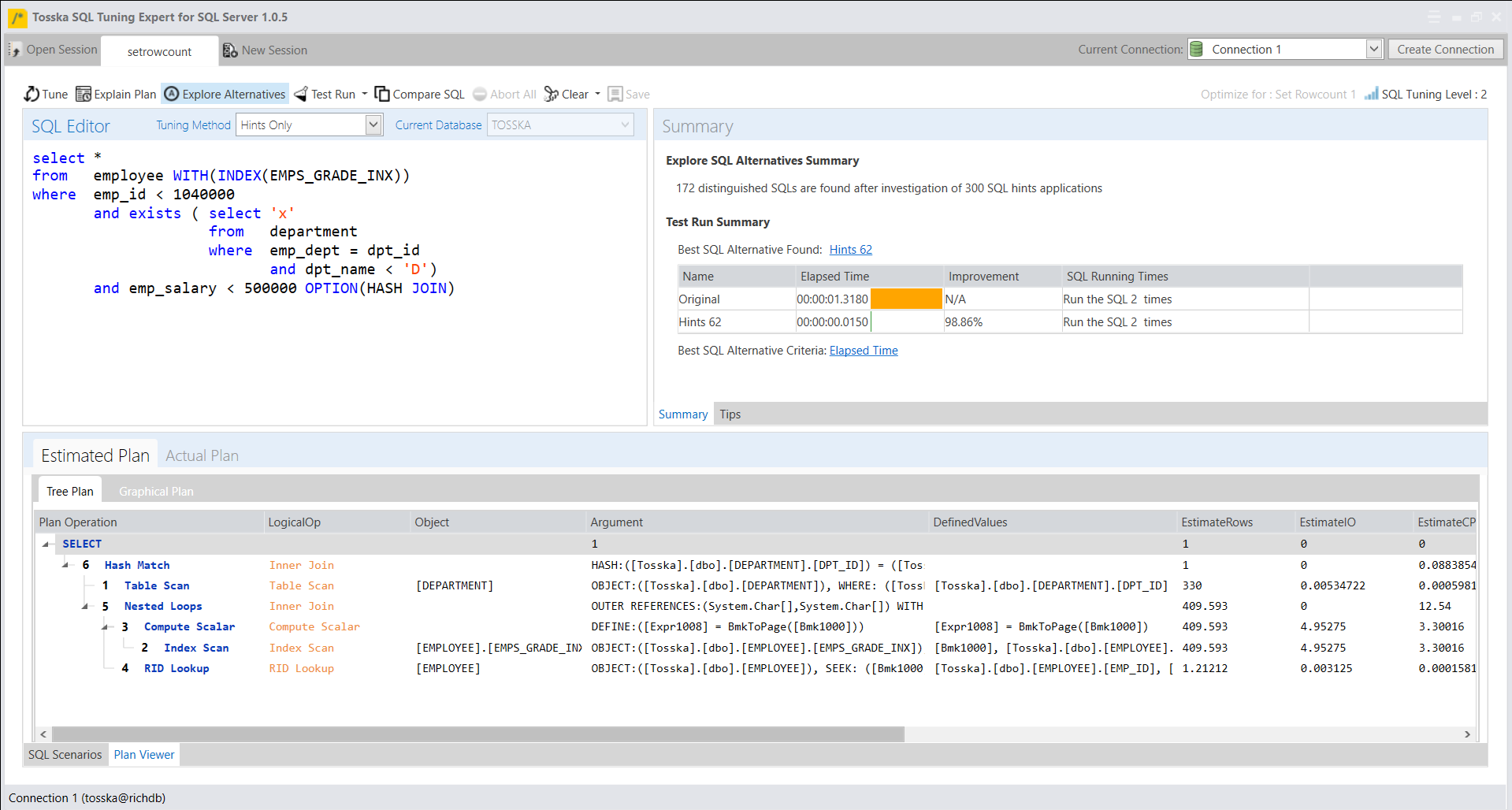
借助最新的 AI 算法,计算机搜索引擎可以极大地释放用户发现提示组合的努力,而无需经历巨大的提示排列空间。它使 hint SQL调优变得更容易,并可以解决比您预期的更多的问题。
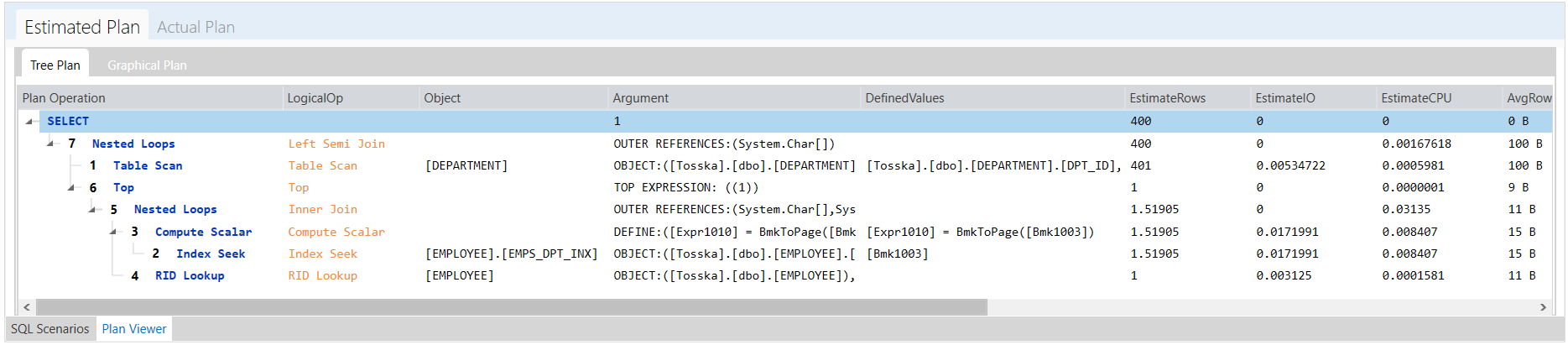
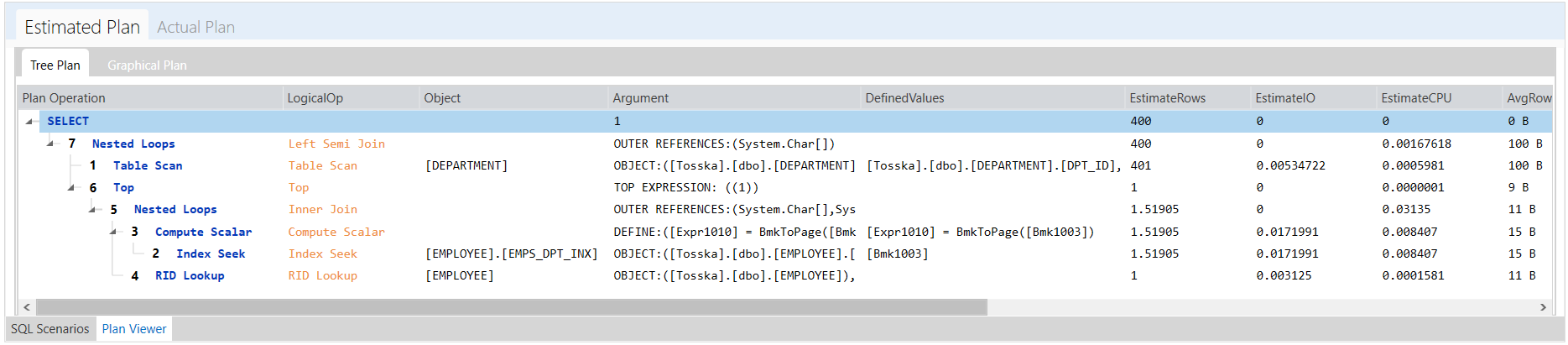
以下解决方案显示了一系列提示组合,这些提示组合告诉 Oracle 不要使用 EMPLOYEES.EMPSS_GRADE_INX 索引和排除哈希联接以联接表,然后使用表 EMPLOYEES 的并行索引扫描。它生成比原始计划快 70% 的新查询计划。整个调优过程无需人工干预即可完成,结果是安全的,因为它不涉及任何语法重写。
https://www.tosska.cn/tosska-sql-tuning-expert-tse-oracle-zh/
Tuning SQL without touching the its SQL text
如果您是一个应用程序用户,您可能想知道,如果无法直接编辑查询,如何调整 SQL。或者,如果您是应用程序开发人员,您希望快速修复 SQL 性能,而无需花时间进行思考源代码更改和单元测试。Oracle 提供了多个功能,例如 SQL 配置文件、SQL Plan Baselines和 SQL Patch, 您可以使用这些功能告诉 Oracle 修复 SQL 的查询计划,而不需要更改SQL文本。但是这些功能的使用仅受 Hints 注入的限制,您不能使用不同的语法重写 SQL,并且要求原始 SQL 接受重写的 SQL 查询计划。因此,在当今瞬息万变的数据库应用程序中,基于Hints的 SQL 调优变得越来越重要。
实际上,SQL 性能应该与应用程序源代码分离,SQL 性能应该易于管理,以便随时随地部署和回滚。它还应该为一个源 SQL 代码进行定制,以适应不同大小的数据库。基于hints的 SQL 调优将是释放 Oracle 数据库 SQL 性能管理潜在功能的关键,在现代数据库 SQL 调优过程中,它变得越来越重要。