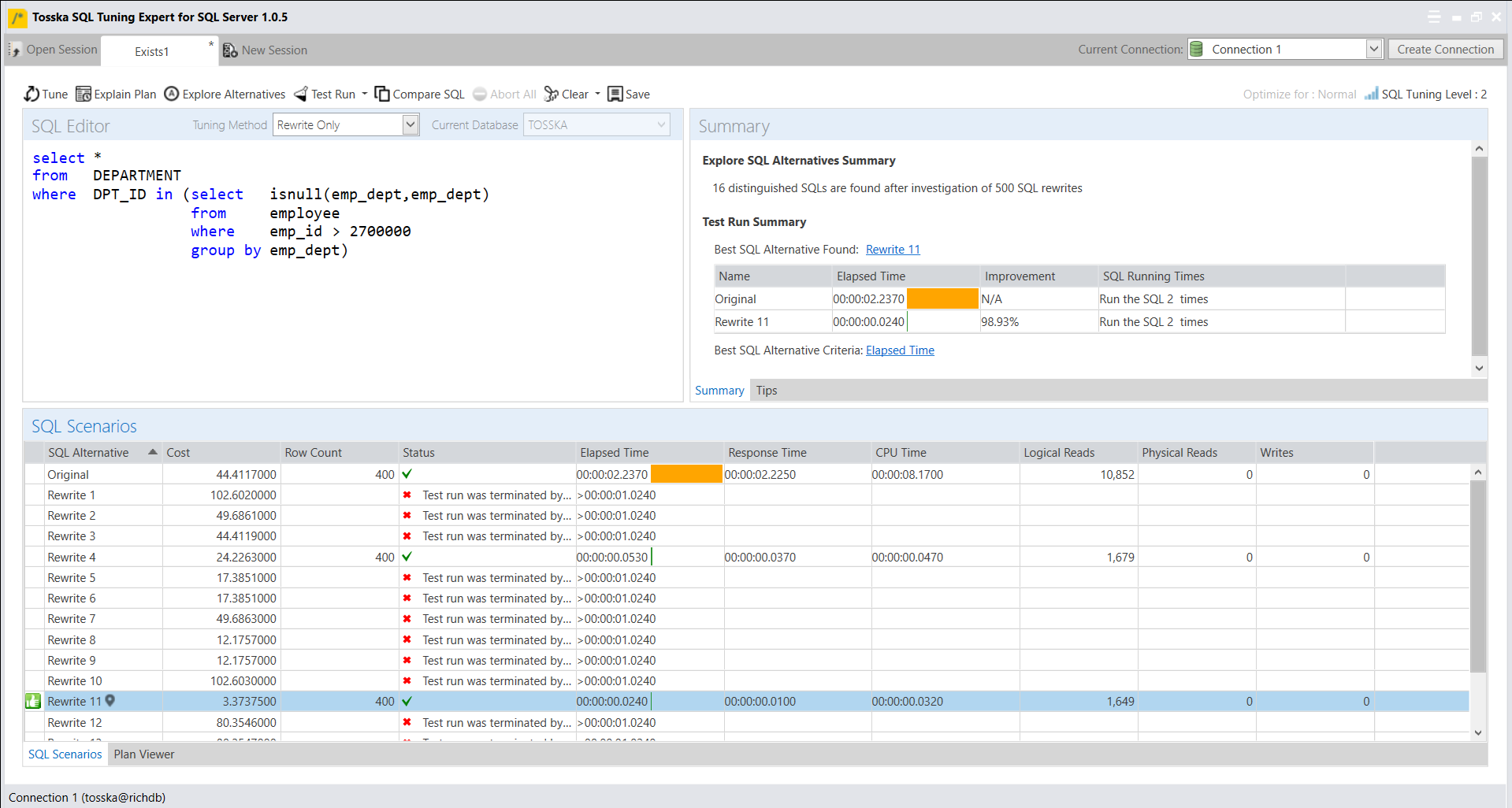
下面示例展示了一个带有Exists子查询的SQL语句。该SQL语句查询DEPARTMENT表中DPT_ID列的值和employee表中emp_dept列的值相等并且employee表中emp_id列的值大于2700000的记录。
SELECT *
FROM DEPARTMENT
where exists (select ‘x’
from employee
where emp_id > 2700000
and emp_dept=DPT_ID)
下面是Tosska树结构执行计划,该sql语句执行需要2.23秒才能完成。
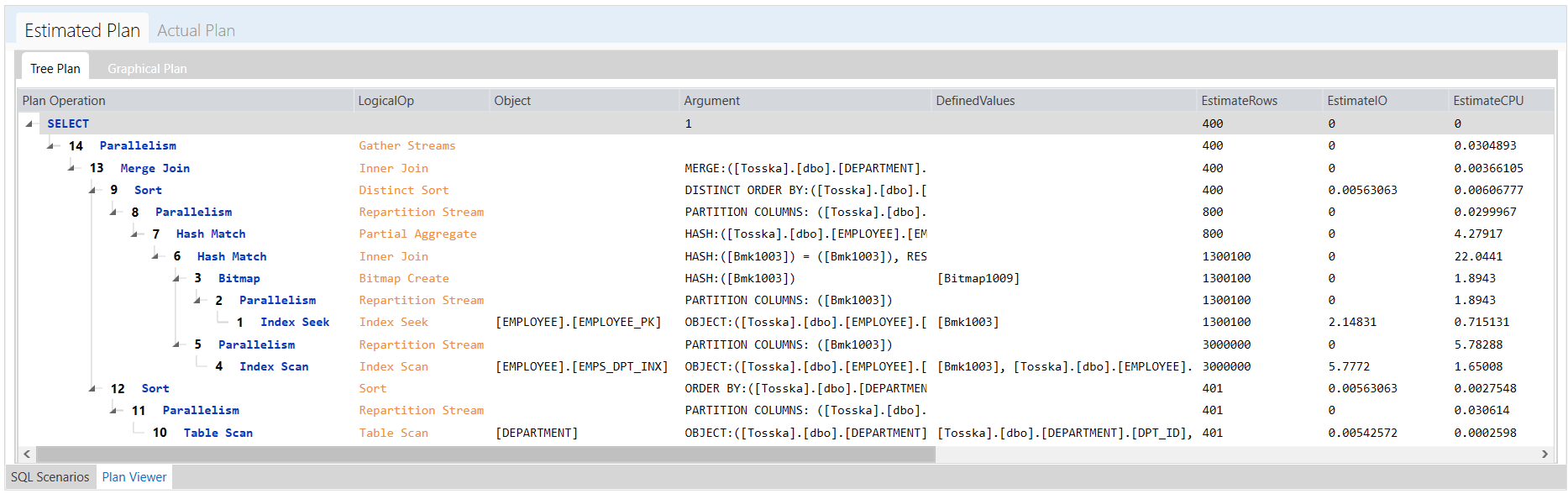
该执行计划显示了从[EMPLOYEE].[EMPLOYEE_PK]到[EMPLOYEE].[EMPS_DPT_INX]的两个哈希匹配,然后合并连接到排序的[DEPARTMENT]表。这个执行计划看起来很合理,但是在第一阶段从[EMPLOYEE]表扫描的记录数太多了,我们可以用比较小的[DEPARTMENT]表去扫描[EMPLOYEE]表来改善这条SQL语句。
下面让我将EXISTS子查询改写为IN子查询,但是执行计划并没有按照预期的改变。
select *
from DEPARTMENT
where DPT_ID in (select emp_dept
from employee
where emp_id > 2700000)
我将进一步的改写SQL,并且添加伪函数“isnull(emp_dept,emp_dept)”到查询列表中,但它不能停止哈希匹配到[EMPLOYEE].[EMPS_DPT_INX]的操作。
select *
from DEPARTMENT
where DPT_ID in (select isnull(emp_dept,emp_dept)
from employee
where emp_id > 2700000)
为了进一步停止“哈希匹配到[EMPLOYEE].[EMPS_DPT_INX]”这一操作,我尝试在子查询中添加“group by emp_dept”伪操作。
select *
from DEPARTMENT
where DPT_ID in (select isnull(emp_dept,emp_dept)
from employee
where emp_id > 2700000)
group by emp_dept)
下面是最终改写后的执行计划,SQL Server首先对[DEPARTMENT]进行表扫描和EMPS_DPT_INX索引从[EMPLOYEE]中寻找RID的嵌套循环操作,因此[DEPARTMENT]表中的每条记录最多匹配一次[EMPLOYEE]。现在的执行速度是0.024秒,比原来的SQL快很多。
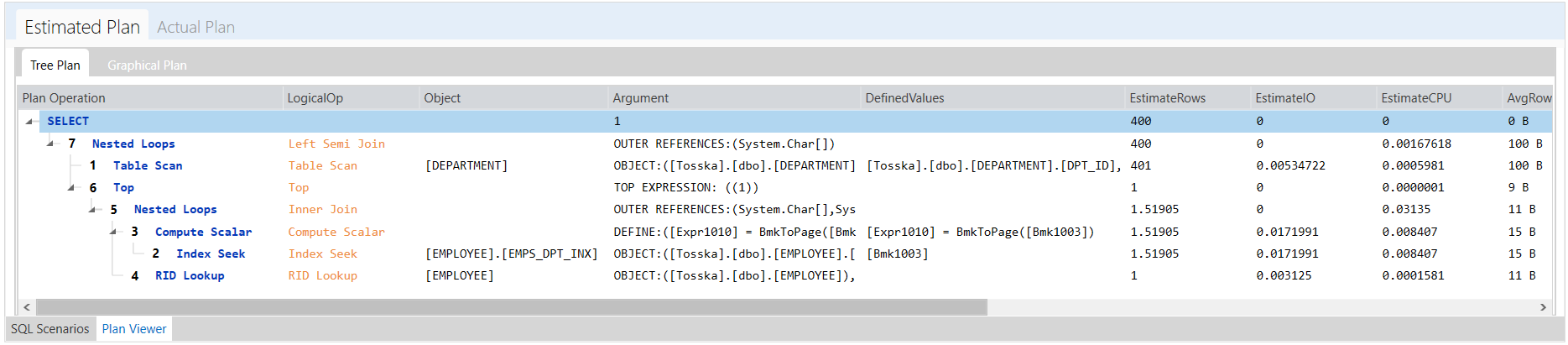
尽管改写的步骤有点复杂,但它可以由Tosska SQL Tuning Expert for SQL Server自动实现,并且它比原始SQL快了90多倍。
Tosska SQL Tuning Expert (TSES™) for SQL Server® – Tosska Technologies Limited