openGauss 是一个开源的关系型数据库管理系统(RDBMS),起源于 PostgreSQL。它专为高性能、高可用性和企业级功能而设计。openGauss 最初由华为开发,后来开源给社区。
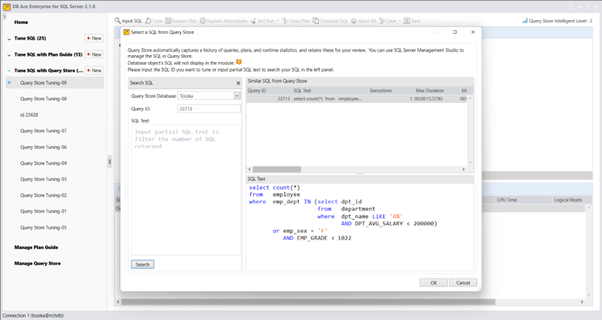
以下是开发人员可能会遇到的一个常见问题:编写动态 SQL 语句时,在 CASE 表达式中硬编码了 a = ‘low’,而不是使用绑定变量 = :var,如下所示:
SELECT *
FROM employee
WHERE
CASE
WHEN emp_salary< 1000
THEN ‘low’
WHEN emp_salary>100000
THEN ‘high’
ELSE ‘Normal’
END = ‘low’
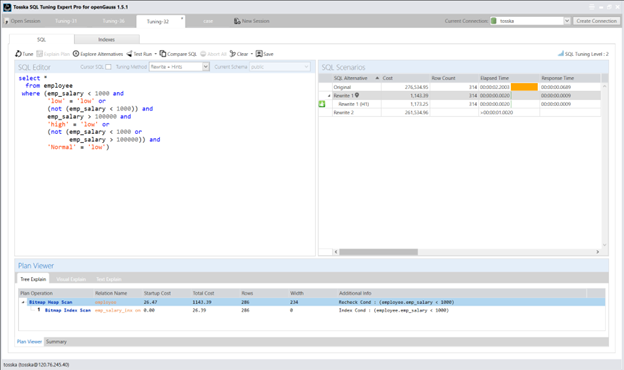
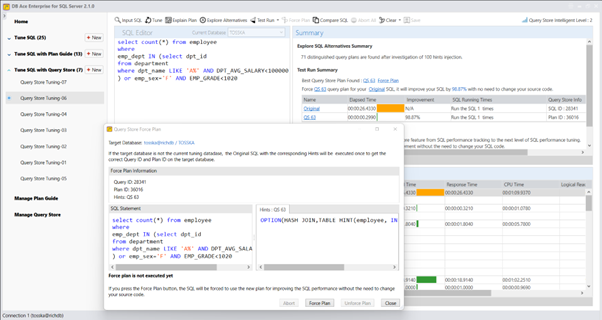
以下是该 SQL 语句的查询计划,其执行时间为 2.20 秒。由于 CASE 表达式无法利用 emp_salary 索引,查询对 EMPLOYEE 表执行了顺序扫描(Seq Scan)。

我们可以使用以下带有多个 OR 条件的语法来重写 CASE 表达式。
select *
from employee
where (emp_salary < 1000 and
‘low’ = ‘low’ or
(not (emp_salary < 1000)) and
emp_salary > 100000 and
‘high’ = ‘low’ or
(not (emp_salary < 1000 or
emp_salary > 100000)) and
‘Normal’ = ‘low’);
如果 emp_salary 字段可为空(nullable),SQL 查询应按照以下方式编写:
select *
from employee
where (emp_salary < 1000 and
‘low’ = ‘low’ or
((not (emp_salary < 1000)) or
emp_salary is null) and
emp_salary > 100000 and
‘high’ = ‘low’ or
((not (emp_salary < 1000 or
emp_salary > 100000)) or
emp_salary is null) and
‘Normal’ = ‘low’)
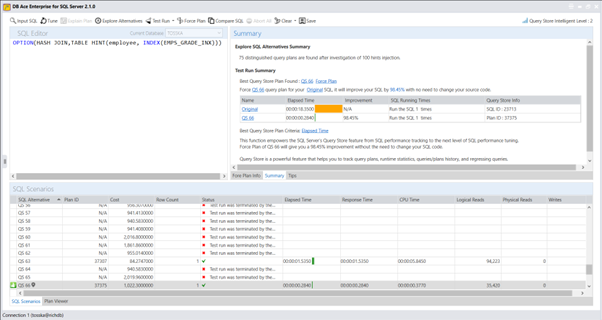
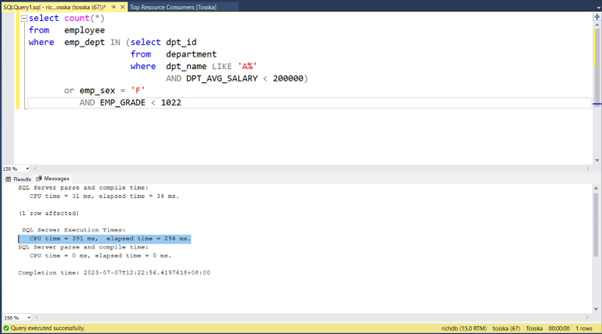
以下是重写后的 SQL 查询计划,其执行时间为 0.002 秒,比原始语法快了 1100 倍。新的查询计划使用了针对 emp_salary 索引的位图索引扫描(Bitmap Index Scan)。
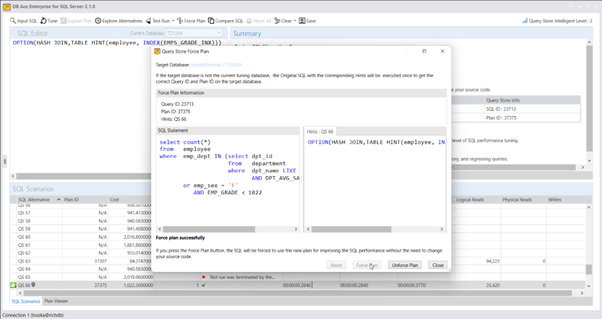
这种重写可以通过 Tosska SQL Tuning Expert Pro 工具为 openGauss 自动实现。还有一些其他重写方法可以提供更好的性能,但由于篇幅限制,本文不适合详细讨论。我可能会在未来的博客文章中进一步探讨这些方法。
Tosska SQL Tuning Expert Pro (TSEG Pro™) for OpenGauss® – Tosska Technologies Limited