介绍
应用程序包软件是为授权给第三方组织而开发的软件程序的集合。虽然软件包软件可以通过参数或表来满足用户的特定需求,但软件本身并不是专门为组织开发的。因此,用户不能拥有源代码,也没有方法修改嵌入式SQL语句来进行性能调优。有很多基于Oracle RDBMS的应用程序包,如Siebel、PeopleSoft JD Edwards、SAP等。为了帮助应用程序包的用户,Oracle提供了一些特性来帮助用户调优SQL语句,且不需要更改源代码。
SQL profile
它是由Oracle SQL Tuning Advisor生成的概要文件。SQL概要文件包含对错误估计的统计信息和辅助信息的更正。因此,SQL profile只是将优化器引导到一个更好的计划,但它们并不保证每次解析语句时都使用相同的计划。对于某些SQL语句,无论统计数据有多好,Oracle SQL optimizer仍然无法在特定的环境中生成更好的计划。对于这些类型的SQL语句,人工干预是必要的,但是对于开发人员来说,SQL profile不是一个方便的工具,在不更改程序源代码的情况下,不能强迫Oracle执行新的计划。
SQL plan baselines and stored outlines
由于Oracle环境的变化或Oracle数据库版本升级,它可能会针对Oracle SQL优化器为某些SQL语句生成新的计划。如果它不好,我们需要一些东西来保存旧的计划,以适应新的环境。为了实现SQL计划的稳定性,stored outlines是Oracle数据库早期版本中的主要工具。Oracle数据库11g仍然支持该特性;但是,在将来的版本中,它可能会贬值,并被SQL计划管理所替代。SQL Plan Baselines的机制是保持指定SQL语句的性能,而不管数据库环境的变化或版本升级。此外,还可以手动为SQL语句创建Plan Baselines,并且该技术可以帮助开发人员指导Oracle SQL优化器为性能较差的SQL语句生成特定的计划。因此,当Oracle SQL optimizer下次接收到相同的SQL语句时,将根据数据库中存储的新计划基线组成更好的性能计划。不需要更改源程序中的SQL语句。
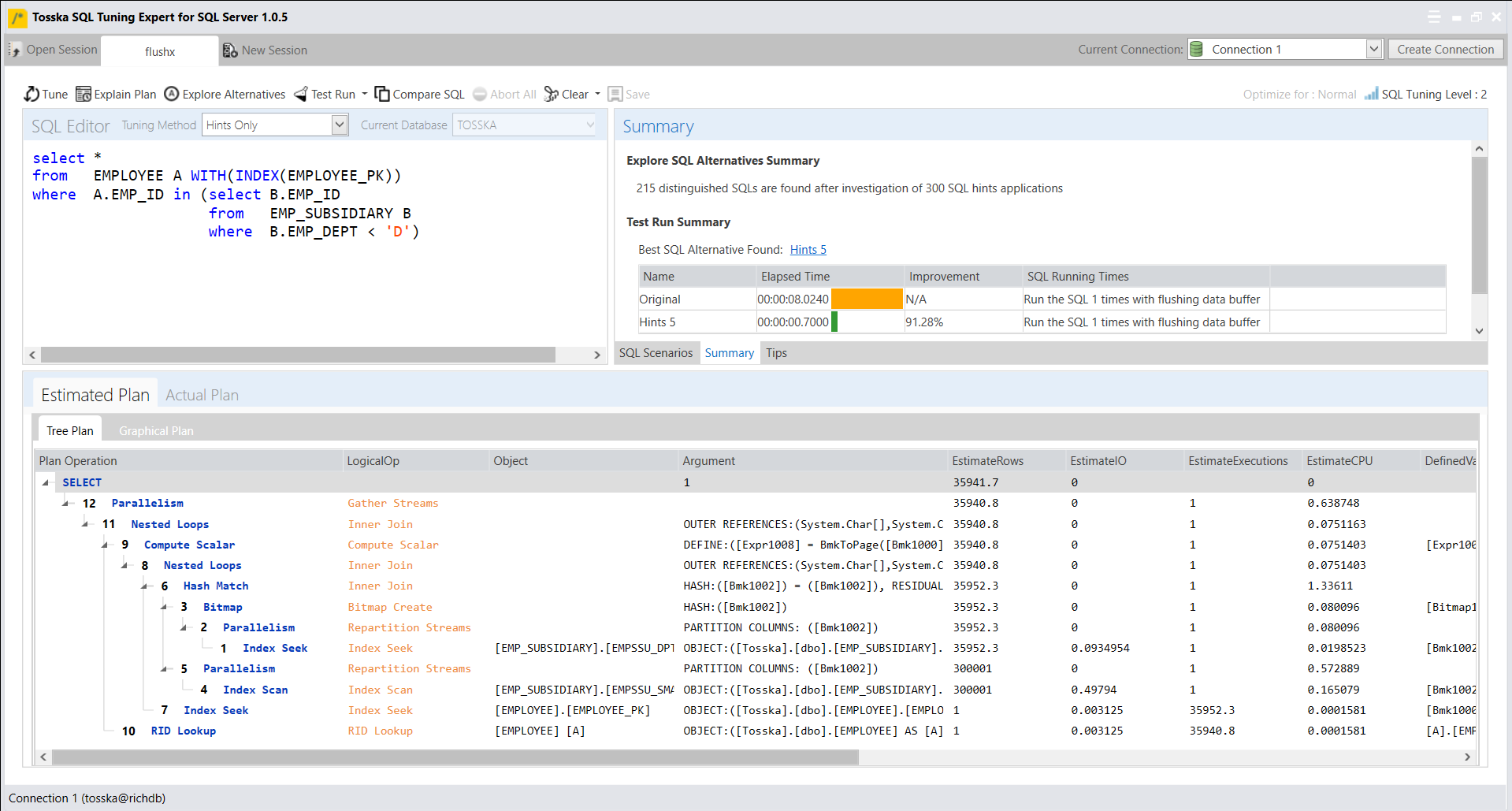
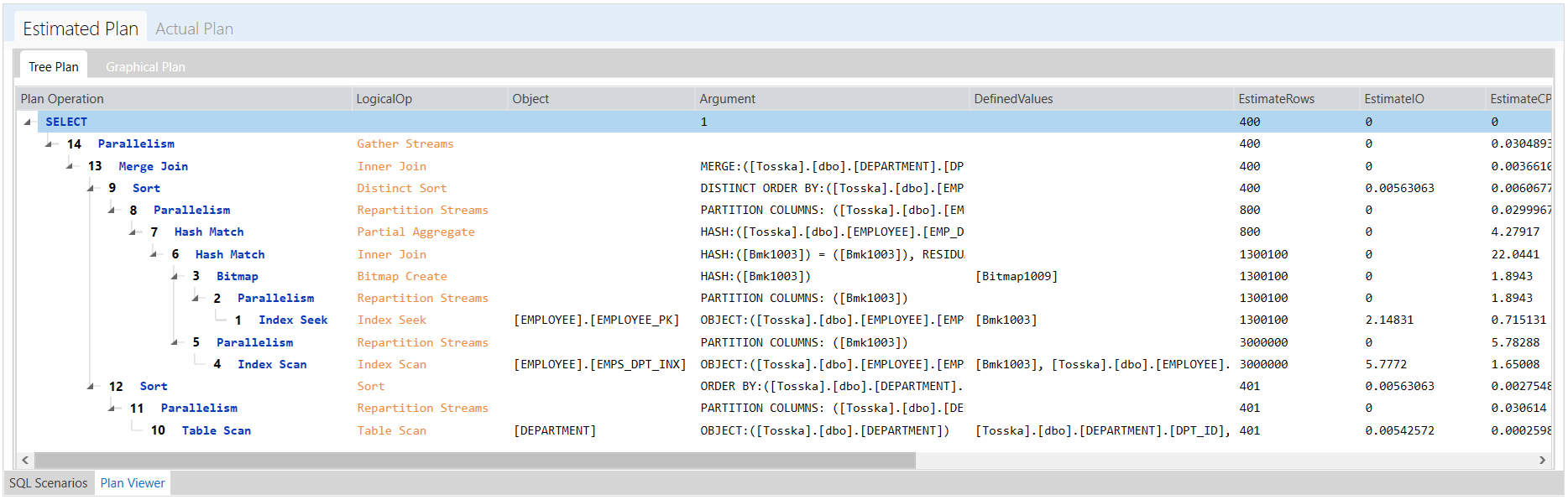
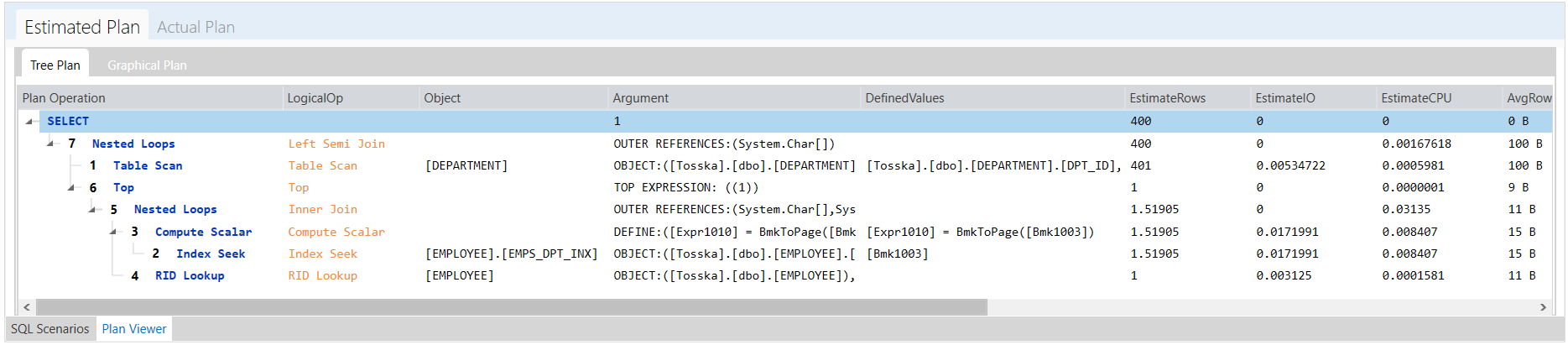
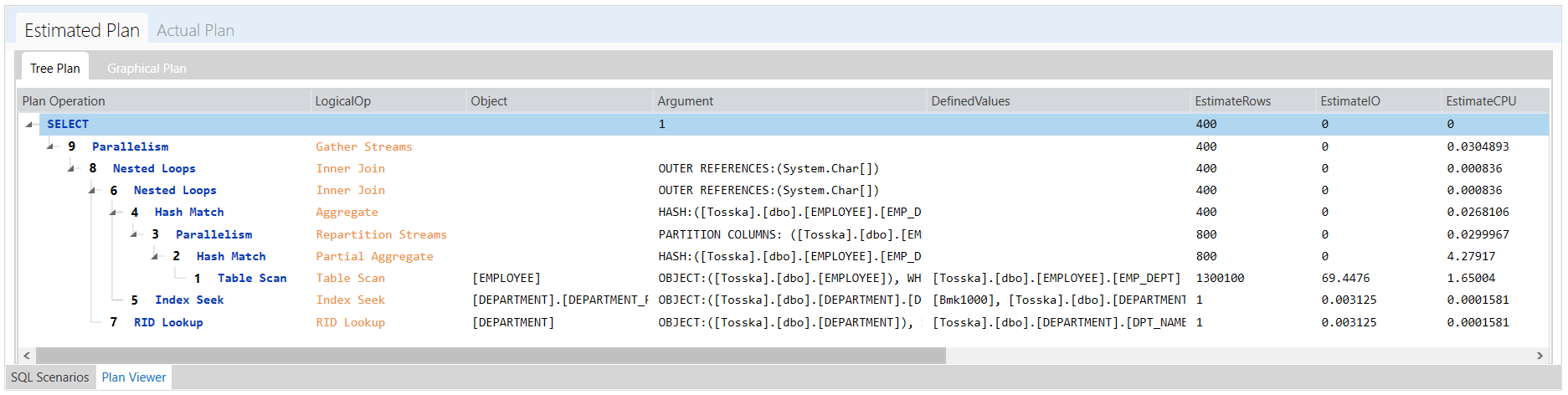
例如,如果您想要调优一条执行plan-A计划的SQL(目前Oracle SQL optimizer在您的数据库中使用这条SQL),并且您想要调优这条SQL(带有提示),使Oracle SQL optimizer生成一个新的计划plan-B。你需要做的是用执行调优后的SQL(带新的提示),并使用Oracle提供的以下方法:
使用优化后带提示的SQL执行,并在SGA中缓存plan B。
SET SERVEROUTPUT ON
DECLARE
My_Plan PLS_INTEGER;
BEGIN
My_Plan := DBMS_SPM.load_plans_from_cursor_cache(
sql_id => 'Plan-B SQL_ID',
plan_hash_value => 'Plan-B plan_hash_value’,
sql_handle => 'Original SQL’s sql_handle');
DBMS_OUTPUT.put_line('Plan Loaded=> ' || My_plan);
END;
要启用调优计划,手动将调优后的计划更改为固定计划,方法是将其FIXED属性设置为YES。
要启用SQL plan baselines,请确保optimizer_use_sql_plan_baslines初始化参数设置为TRUE。
使用SQL Plan baselines进行SQL调优的缺点
由于SQL Plan baselines的设计目的是为了在以下环境发生变化后保持SQL语句的性能:
- 新的优化器版本
- 更改优化器统计信息和优化器参数
- 更改schema和元数据定义
- 更改系统设置
- SQL profile 创建
您可以看到,它不是为手动SQL调优而设计的。还有一些额外的限制,比如SQL Plan Baselines不支持Parallel Hints,您不能为你的SQL加载一个应用Parallel Hints的Plan-B,而原始计划Plan-A的性能很差。 有时候, Parallel Hints 在Oracle SQL optimizer中往往能生成更好的计划。
SQL Patches
SQL Patches是SQL Repair Advisor提供的特性之一,用于修复SQL语句的关键故障,比如返回错误的结果。 SQL Repair Advisor分析有问题的语句,并在许多情况下建议使用SQL patch来修复该语句。SQL patch将影响Oracle SQL优化器为将来的执行选择一个替代的执行计划,而不是使用原来有问题的执行计划。在Oracle Database 12c Release 2之后,提供了一个公共API来手动创建SQL patch。DBMS_SQLDIAG.CREATE_SQL_PATCH包可以帮助用户为特定的SQL语句创建用于SQL调优的SQL patch。你可以改变一个性能不好的SQL语句的执行计划,而不需要修改程序源代码, 如下:
DECLARE
Patch_name VARCHAR2(32767);
BEGIN
Patch_name := SYS.DBMS_SQLDIAG.create_sql_patch(
sql_text => 'SELECT *
FROM employees
WHERE emps_dept IN
(SELECT dpts_id
FROM departments
WHERE dpts_avg_salary <200000)', hint_text => 'INDEX(@SEL$1 EMPLOYEES) INDEX(@SEL$2 DEPARTMENTS)',
name => 'my_sql_patch_name');
END;
如果数据库版本在Oracle database 12c Release 2之前,则必须使用DBMS_SQLDIAG_INTERNAL.i_create_patch包代替。SQL文本和SQL ID都可以用于SQL提示注入。为SQL注入的提示应该放在hint_text输入参数中。只有一行 Hints 文本可以用于SQL,而且无法为任何子查询块定义自己的查询块名称。因此,如果您的SQL有多个子查询,并且希望指示Oracle在子查询的块中执行某些操作,则必须在注入的 Hints 文本中使用Oracle默认的查询块名称。
hint_text => ‘ INDEX(@SEL$1 EMPLOYEES) INDEX(@SEL$2 DEPARTMENTS) ‘
上面示例中的提示文本显示@SEL$1和@SEL$2是Oracle在SQL执行计划中提供的默认查询块名称。提示告诉Oracle使用索引搜索查询块@SEL$1中的EMPLOYEES表,同时使用索引搜索查询块@SEL$2中的DEPARTMENTS表。
使用SQL Patches来调优SQL的优缺点
没有SQL Plan Baselines的限制,SQL patch更灵活地接受提示指令,带parallel操作的复杂提示通常能被SQL patch接受。在创建 SQL Patches之后,不需要额外的维护工作来告诉Oracle使用 SQL Patches。 Oracle将使用存储的提示优化任何具有相同SQL ID或SQL文本的SQL,并生成更好的性能执行计划。此外,您还可以使用 SQL Patches 来禁用已在包应用程序中写入的破坏性提示的 SQL,甚至使用它来控制一个具有绑定感知的SQL的执行行为。
由于注入的提示文本必须放在一个文本行中,并且只使用默认的查询块名称,因此手工编写一个预期的提示来改进SQL语句,对于大多数SQL开发人员来说是一项困难的任务,尤其是对于包含许多子查询的复杂SQL语句。
一个自动创建Hints和SQL Patches的工具
到目前为止,市场上只有一个工具能够生成更好的提示且完全自动化的方式创建SQL Patch。
Tosska SQL Tuning Expert Pro 是一个用户可以在不接触其程序源代码的情况下提高 SQL 性能的工具。用户可以为不同大小的生产数据库部署不同的性能查询计划,而不需要保存程序源代码的多个版本,并且特别适合于不拥有其应用程序源代码的包应用程序用户。该工具将尝试最有用的提示组合来调优性能较差的SQL语句,最好的提示组合SQL性能将与原始SQL并排进行基准测试。用户将得到准确的性能改进,没有任何猜测或不确定的成本评估。
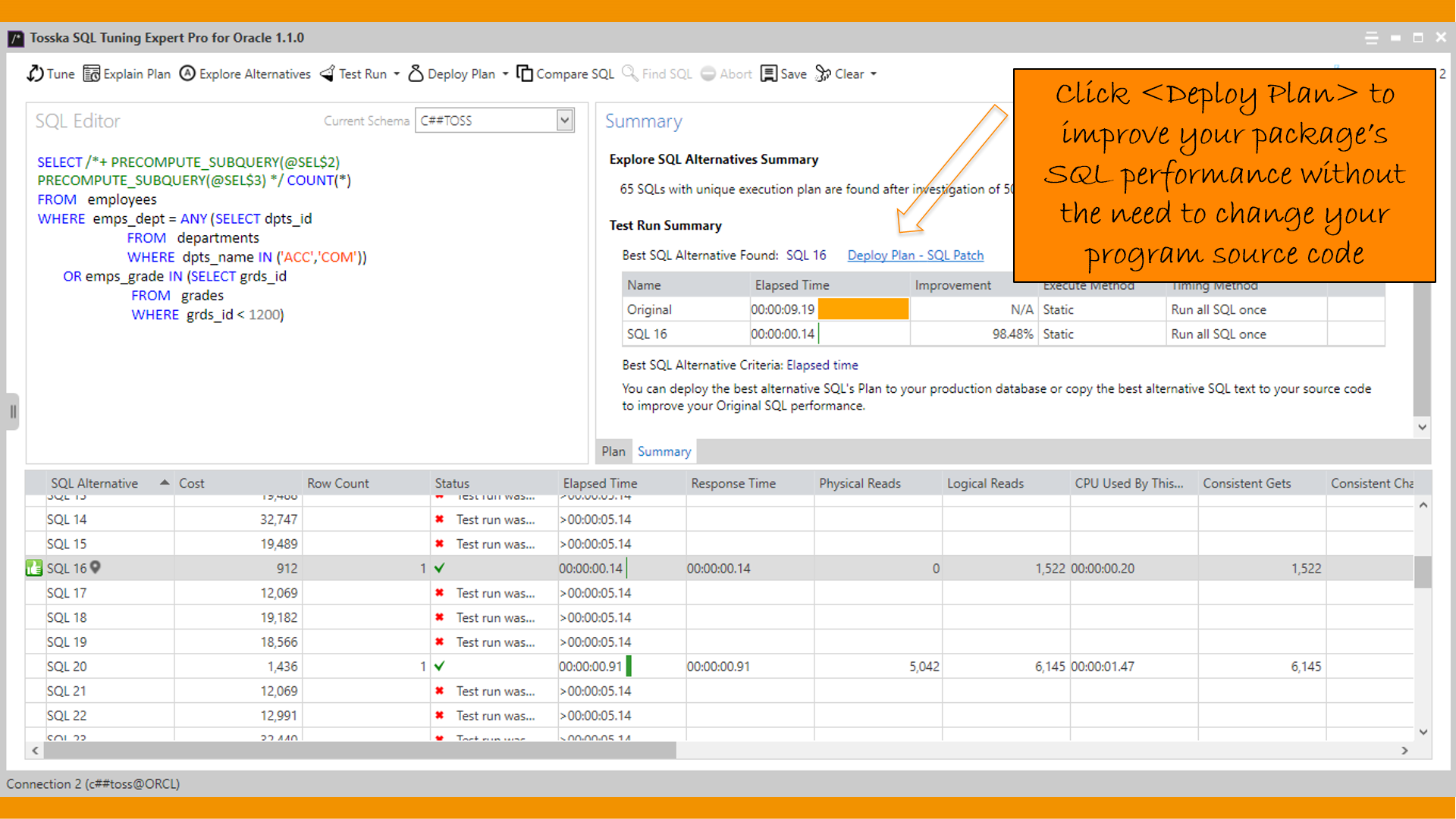
您可以访问我们的网站了解产品详情
https://www.tosska.cn/tosska-sql-tuning-expert-pro-tse-pro-for-oracle-zh/