单击以查看Tosska SQL Tuning Expert(TSES™)for SQL Server 1.5.1发行说明
Tosska SQL Tuning Expert(TSES™)for SQL Server 1.5.1 发行说明


非常智慧
下面示例显示带有EXISTS子查询的SQL语句。如果在DEPARTMENT表的子查询中满足OR条件,SQL会对EMPLOYEE表中的记录进行计数。
select countn(*) from employee a where
exists (select ‘x’ from department b
where a.emp_id=b.dpt_manager or a.emp_salary=b.dpt_avg_salary
)
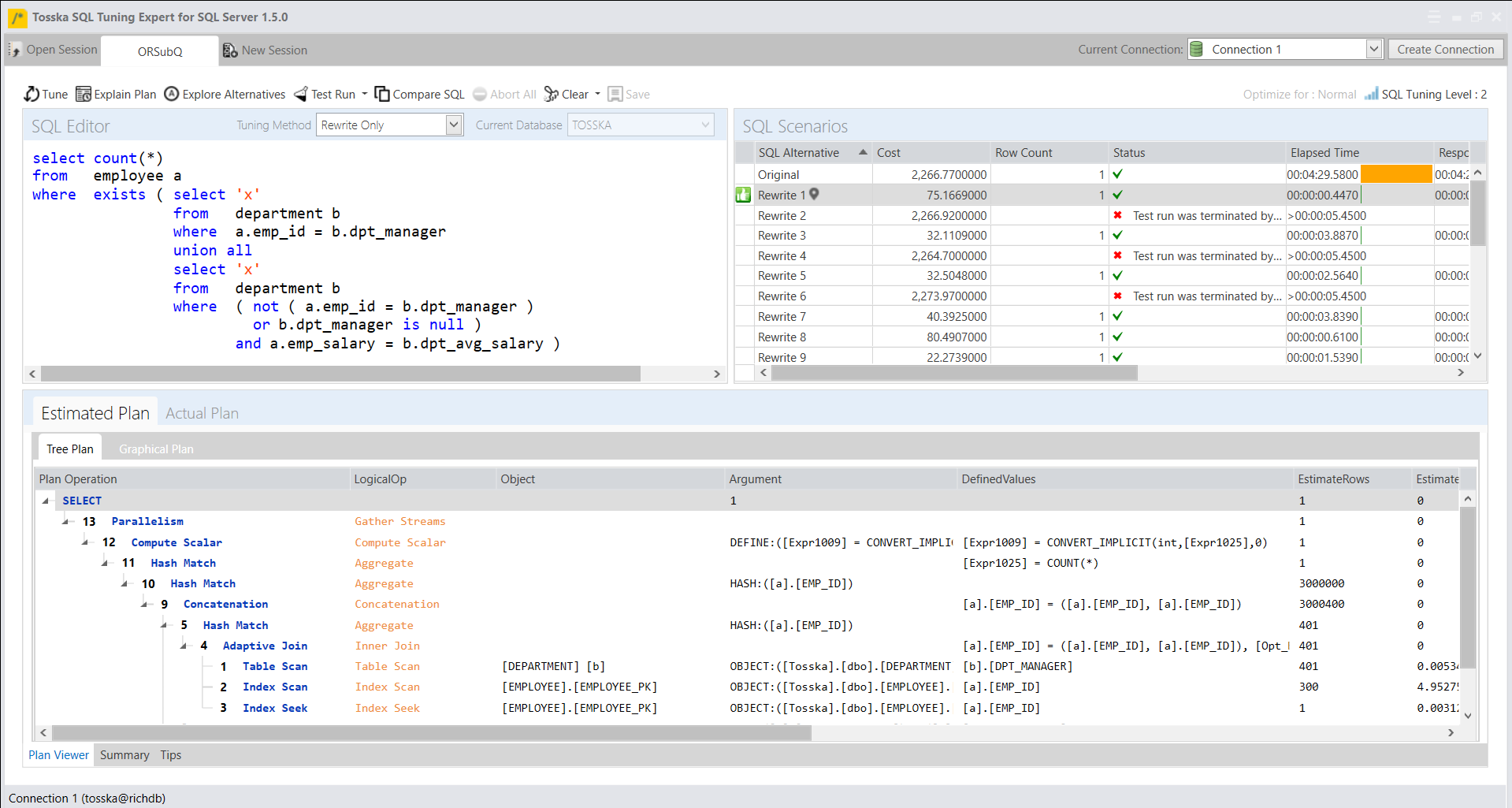
下面是Tosska专有的树结构执行计划,它需要4分29秒才能完成。
该执行计划显示了从EMPLOYEE到全表扫描DEPARTMENT表的嵌套循环,这是整个执行计划的主要问题。因为 SQL Server 无法通过其他连接操作来解决这个OR条件“a.emp_id=b.dpt_manager or a.emp_salary=b.dpt_avg_salary”。
下面我将子查询中的OR条件改写为UNION ALL子查询,子查询中UNION ALL的第一部分表示“a.emp_id=b.dpt_manager”条件,第二部分表示“a.emp_salary=b.dpt_avg_salary”条件,但排除已经满足第一个条件的数据。
select count(*)
from employee a
where exists ( select ‘x’
from department b
where a.emp_id = b.dpt_manager
union all
select ‘x’
from department b
where ( not ( a.emp_id = b.dpt_manager )
or b.dpt_manager is null )
and a.emp_salary = b.dpt_avg_salary )
下面是改写后SQL的执行计划,看起来有点复杂,但现在性能很好,只需要0.447秒。有两个散列匹配连接用于替换原来从EMPLOYEE表到全表扫描DEPARTMENT表的嵌套循环。
虽然最终改写的步骤有点复杂,但这种改写可以由Tosska SQL Tuning Expert for SQL Server自动完成,这表明该改写SQL比原始SQL快了600多倍。
Tosska SQL Tuning Expert (TSES™) for SQL Server® – Tosska Technologies Limited
在安装 Tosska SQL Tuning Expert (TSES™) for SQL Server® 之前, 请确保您的系统满足以下最低硬件和软件要求:
| CPU | 1.8 GHz Processor |
| Memory | 2 GB of RAM minimum, 4 GB of RAM recommended |
| Hard Disk Space | 500 MB of disk space for 64-bit installation |
| Operating System | Microsoft Windows® 7 64-bit Microsoft Windows® 10 64-bit |
| .NET Framework | Microsoft .NET Framework 4.5.0 |
| Database Server | SQL Server database 2005 or higher |

在设置返回行数或者使用Top关键字后,某些SQL语句会运行的非常慢。设置返回行数和使用Top关键字会告诉SQL Server从SQL语句中选择特定行数而不是提取所有记录。没有多少人知道在设置返回行数或者使用Top关键字后SQL Server会尝试重新优化您的SQL语句,重新优化后的SQL语句产生的执行计划通常可以更快的检索前几条记录,但是也可能适得其反。
设置返回行数重新优化查询的好示例
下面是一个示例,显示了该SQL从数据库中检索217500行记录需要6.78秒。这是一个好的执行计划,因为它对[DEPARTMENT]和[EMPLOYEE]的两个表扫描进行哈希匹配。
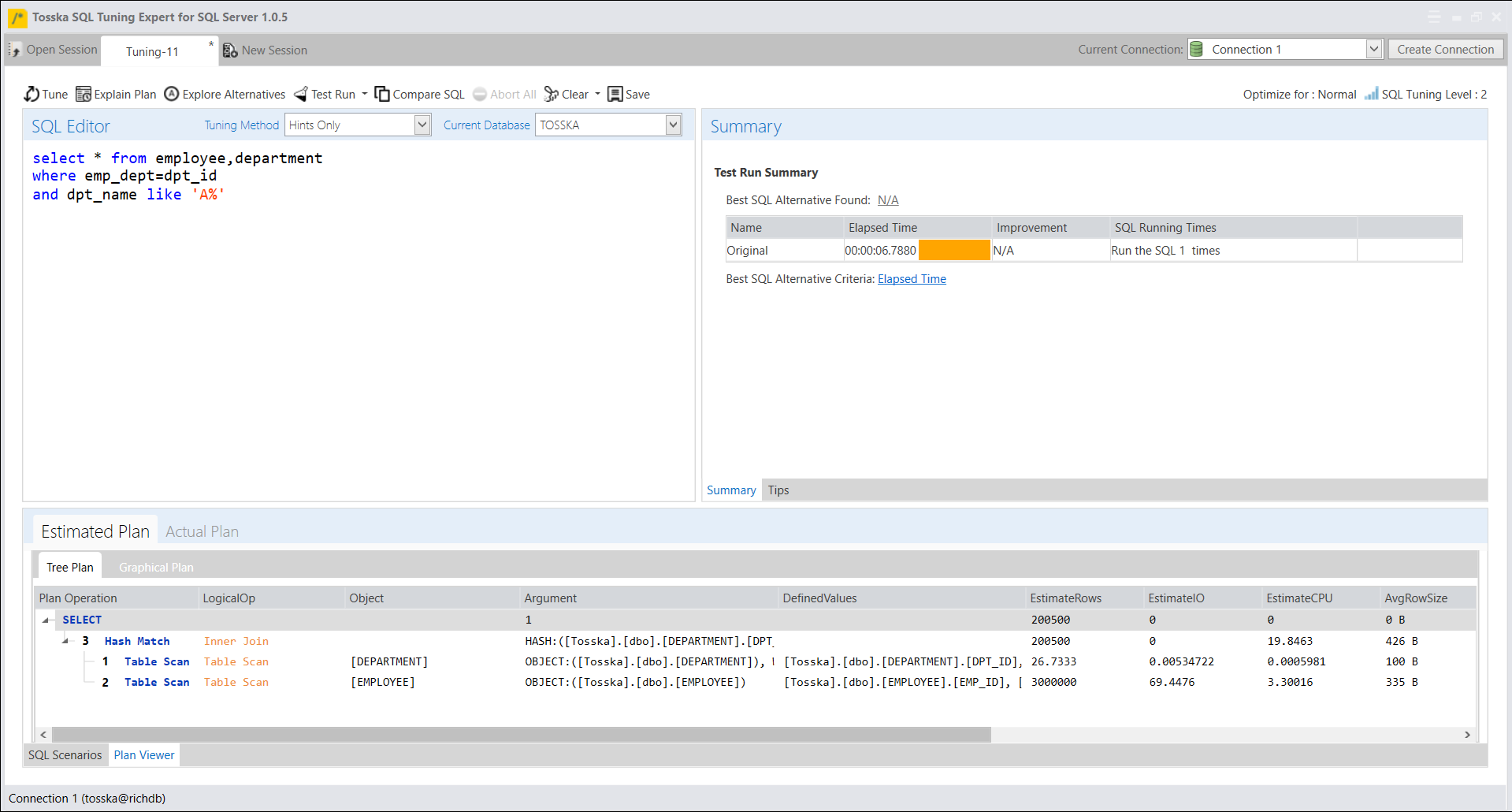
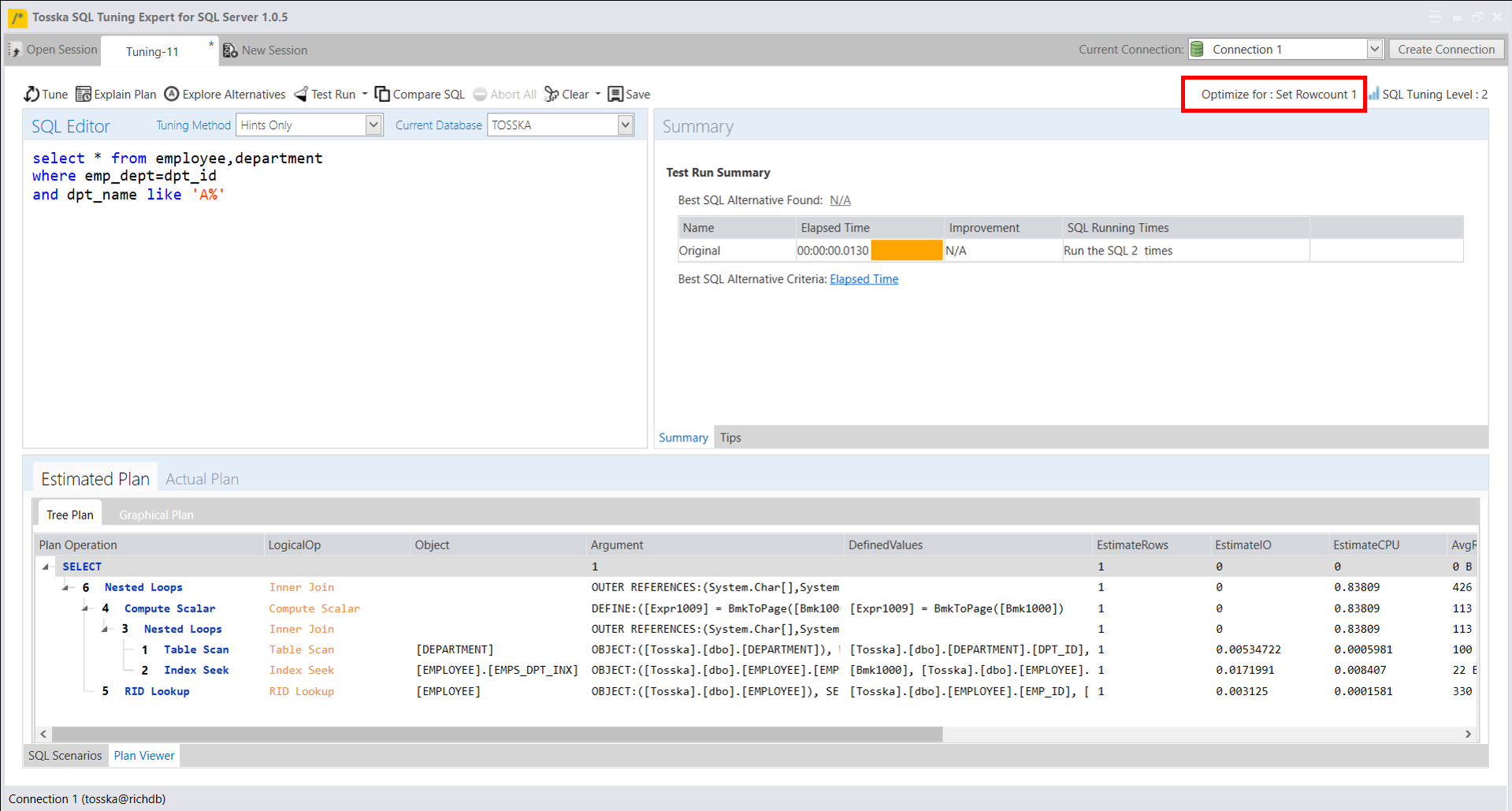
下面屏幕显示了设置返回行数为1后新的执行计划把哈希匹配改为嵌套循环。嵌套循环操作通常提供更快的前几条记录检索时间,但在某些情况下可能不利于整体记录的提取。很高兴看到SQL Server提取此SQL的第一行记录仅用了0.013秒。
设置返回行数重新优化查询的坏示例
让我们来看一个坏示例,它展示了在使用设置返回行数为1后,SQL Server如何将一个好的执行计划变成一个糟糕的执行计划。下面一个示例显示,该SQL从数据库中检索1613行记录花费了0.118秒,虽然该执行计划有点复杂,但对于检索完所有行来说是一个很好的执行计划。
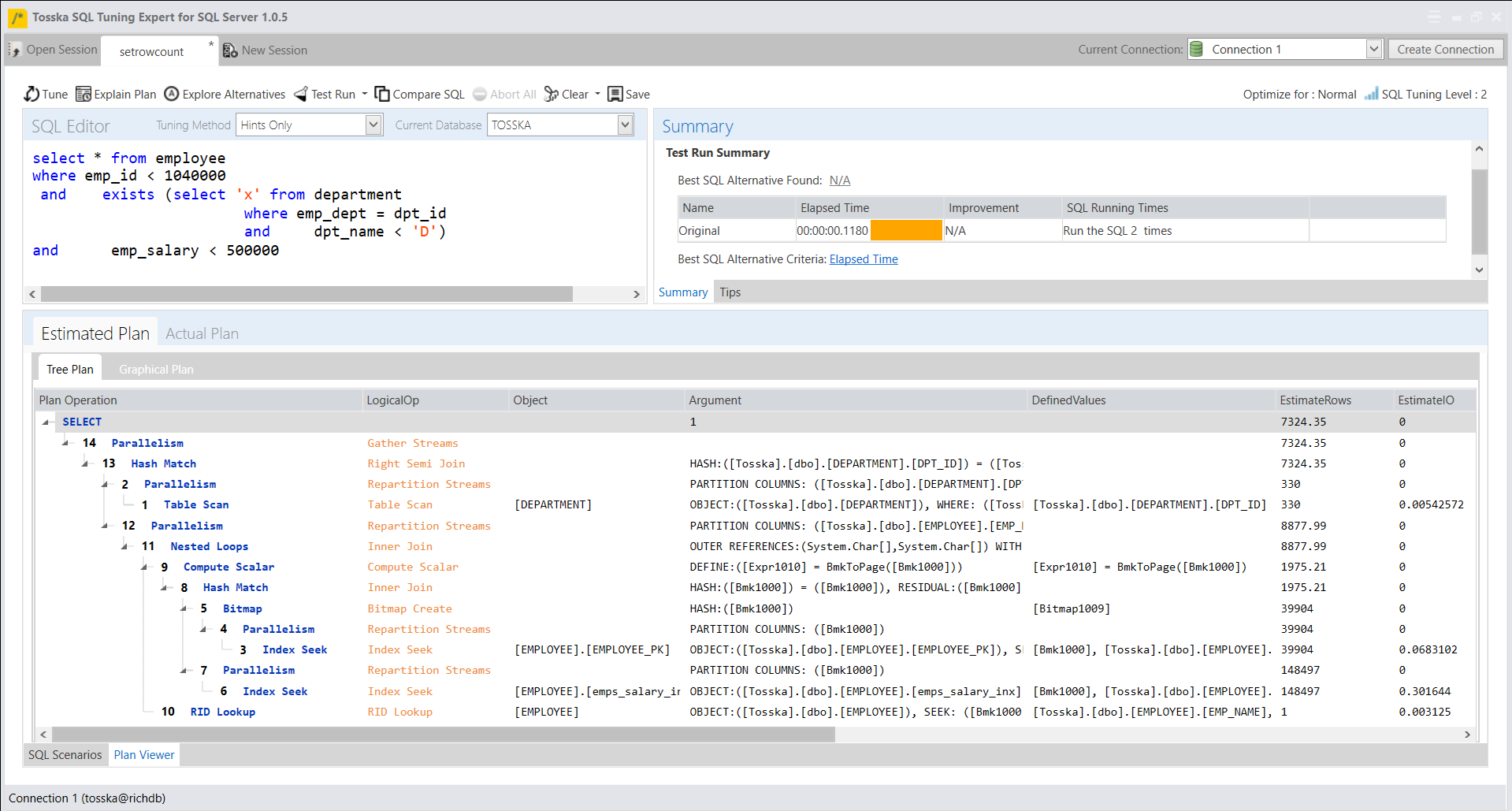
下面屏幕显示了设置返回行数为1后生成的新执行计划,该执行计划现在更改为带有两次表扫描的嵌套循环。新的执行计划提取第一条记录需要1.312秒,比从数据库提取所有行所用的0.118秒还要慢。
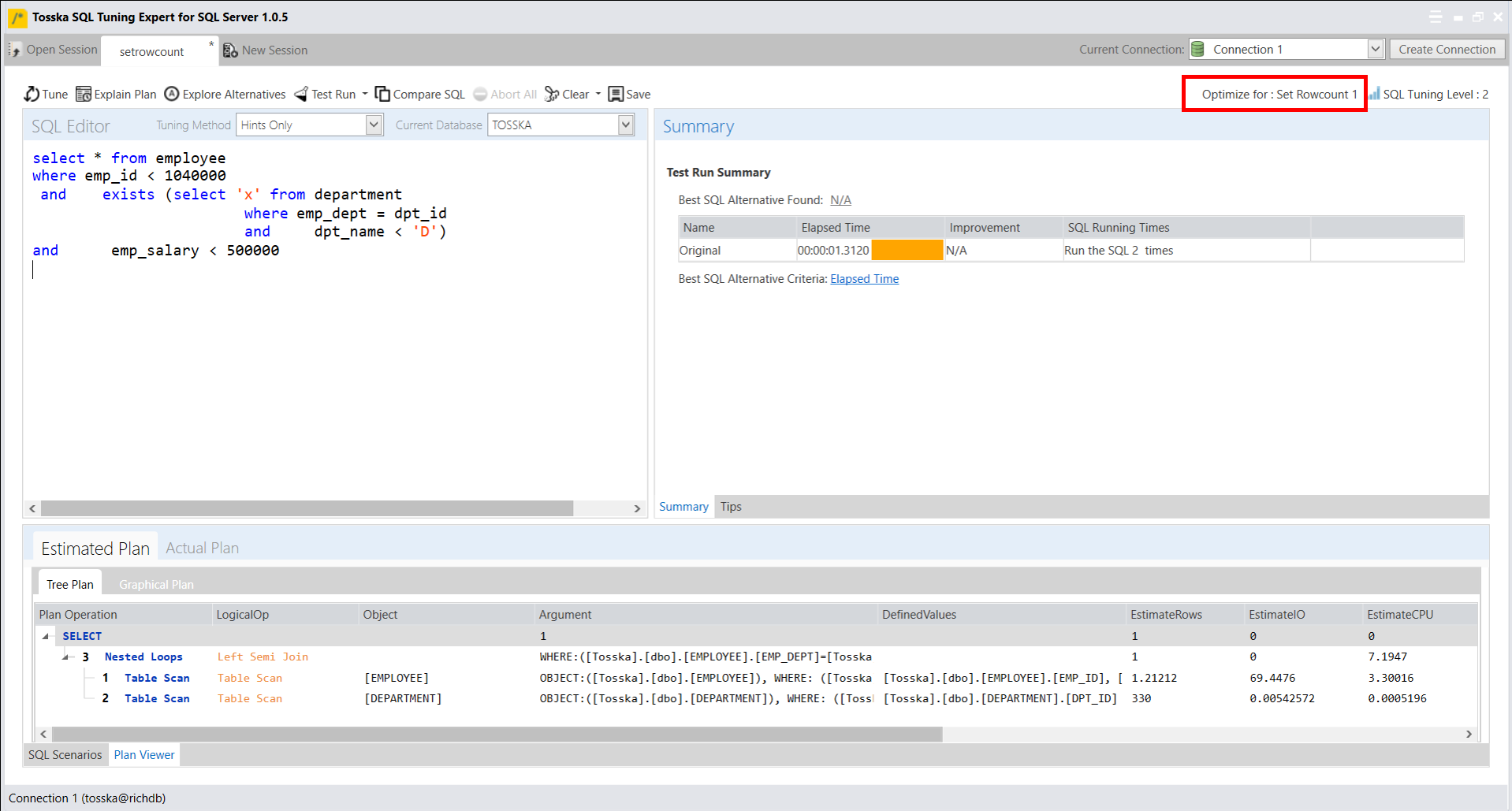
如何解决这个问题呢?
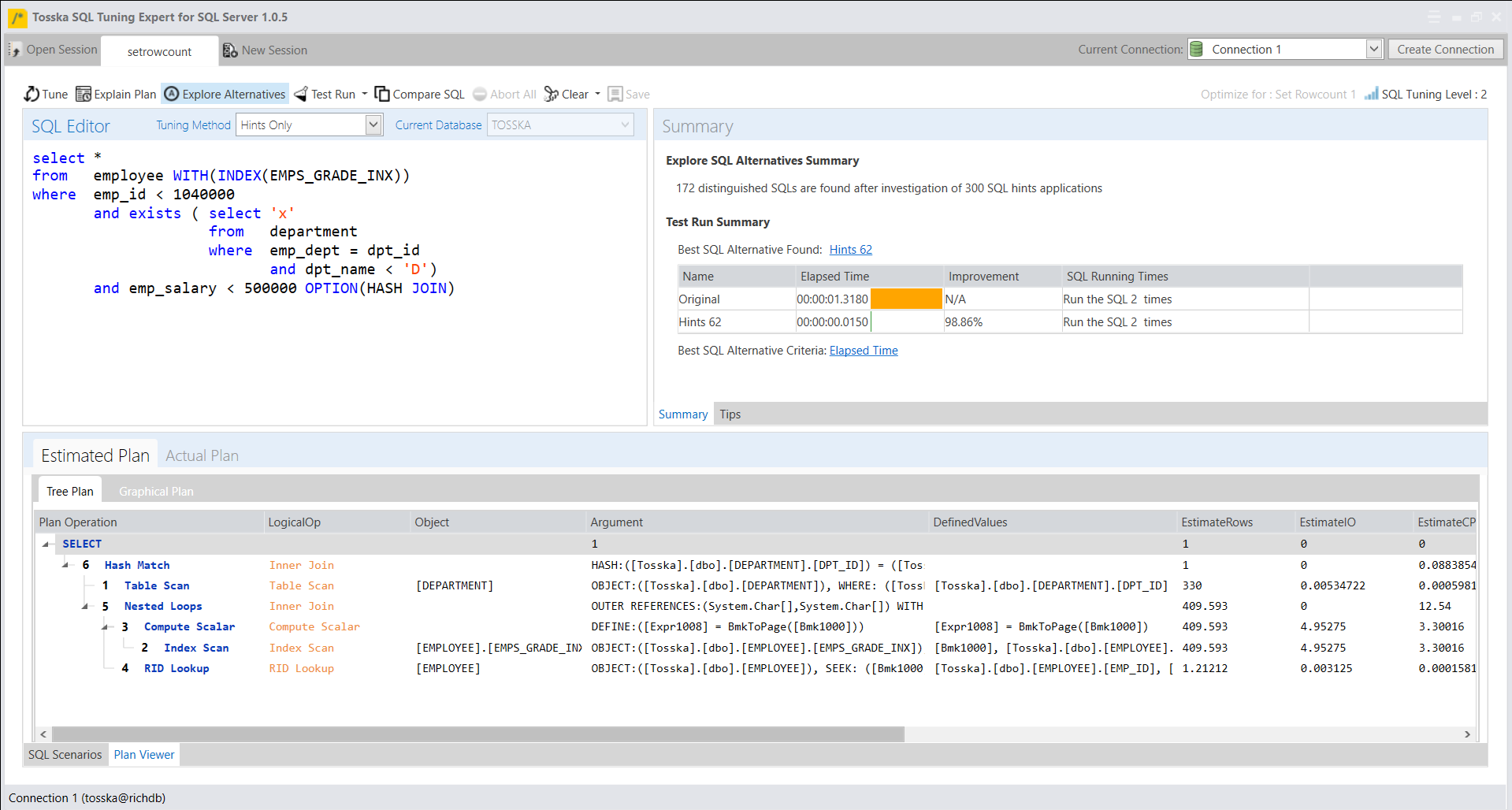
我们可以使用提示注入或者SQL语法改写来影响SQL Server为设置返回行数或者Top关键字操作改回原始的执行计划或者生成更好的执行计划。下面是提示注入生成的一个很好的执行计划,它比设置返回行数为1的原始SQL快了90倍。
Tosska SQL Tuning Expert (TSES™) for SQL Server® – Tosska Technologies Limited

对于不经常执行的SQL语句,相关的数据可能不在缓存区,冷缓存会显著的影响这类SQL语句的性能。 用于热缓存的高性能SQL语句在冷缓存环境中可能表现的不好。经验丰富的开发人员会调优他们的SQL, 使其在两种情况下都能得到良好运行。
下面是一个SQL示例:
select * from
EMPLOYEE A
where A.EMP_ID IN (SELECT B.EMP_ID from EMP_SUBSIDIARY B
where B.EMP_DEPT < ‘D’)
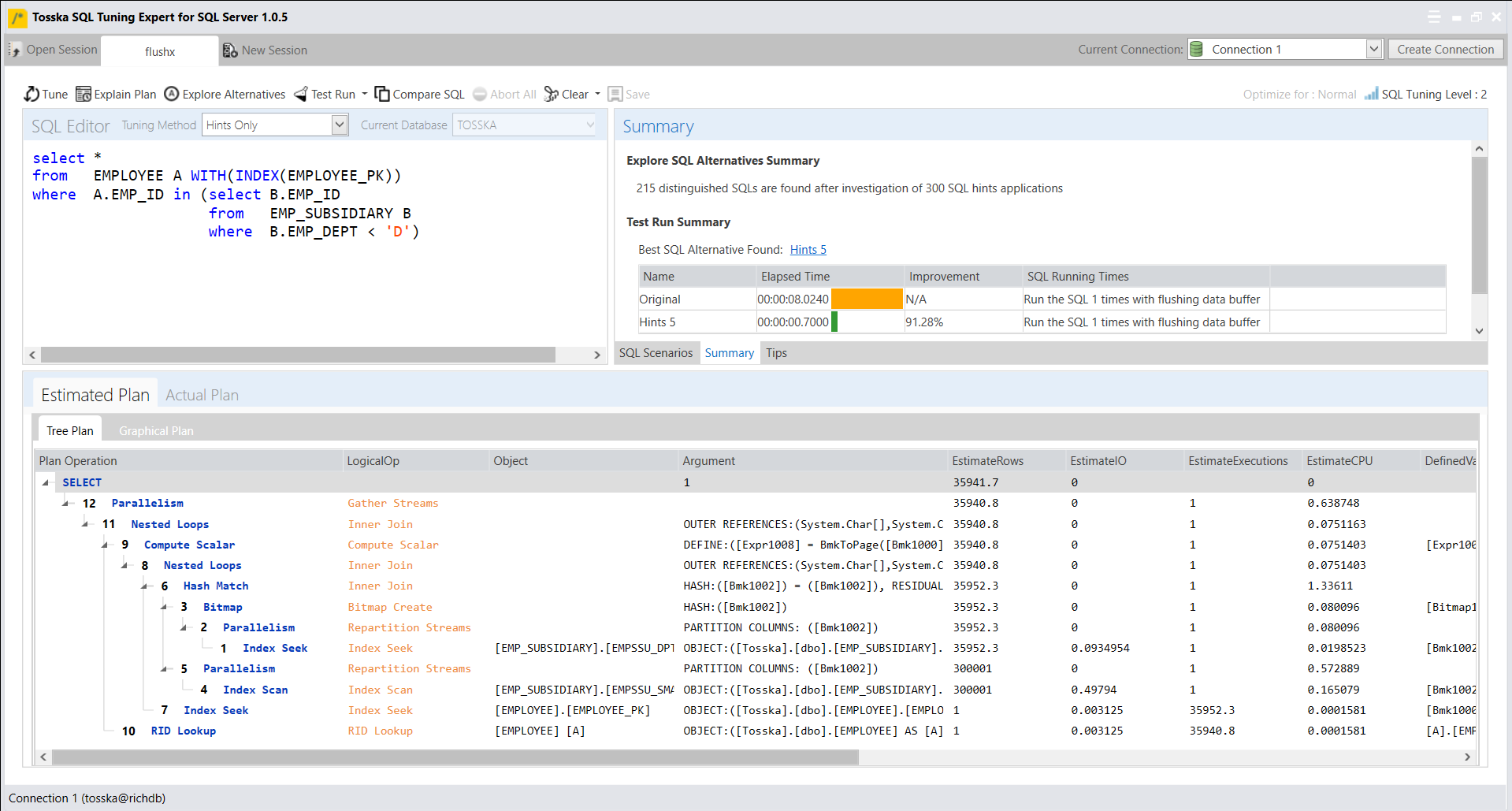
下面是Tosska的树结构执行计划,第一次执行因为缓存延迟需要8.024秒,第二次执行无需缓存延迟只需要3.7秒。

根据执行计划,您可能发现IO消耗最多的是[EMPLOYEE]表的表扫描。为了模拟冷缓存环境,我们可以在每次执行SQL语句前使用DBCC DROPCLEANBUFFERS命令来清除数据缓存。
让我为这条SQL添加OPTION(LOOP JOIN)提示,并尝试将执行计划的哈希匹配更改为嵌套循环连接。因此,将使用[EMPLOYEE]的EMP_ID(EMPLOYEE_PK)和RID查找,而不是使用表扫描。我希望RID查找可以从硬盘中选择较少的数据,同时在[EMPLOYEE]和[EMP_SUBSIDIARY]中匹配EMP_ID。
select *
from EMPLOYEE A
where A.EMP_ID in (select B.EMP_ID
from EMP_SUBSIDIARY B
where B.EMP_DEPT < ‘D’) OPTION(LOOP JOIN)
根据下面的执行计划,携带数据缓存开销的执行时间从8.024秒减少到1.565秒,物理读也从190,621减少到39,044。如果您用SQL Server的EstimateIO乘以EstimiateExecutions来得到IO估计值,这是错误的。

下面的人工智能调优工具还提供了其它更好的调优解决方案:
Tosska SQL Tuning Expert (TSES™) for SQL Server® – Tosska Technologies Limited
下面带有提示的SQL语句生成一个更复杂的执行计划,最好的执行时间为0.7秒。该SQL是在冷缓存下进行调优的,每次执行SQL语句之前都会清除缓存数据。

在我上一篇文章中,带有Exists子查询的SQL语句通过以下改写执行速度快了90倍。
SELECT *
FROM DEPARTMENT
where exists (select ‘x’
from employee
where emp_id > 2700000
and emp_dept=DPT_ID)
执行计划:
改写的SQL语句:
select *
from DEPARTMENT
where DPT_ID in (select isnull(emp_dept,emp_dept)
from employee
where emp_id > 2700000)
group by emp_dept)
执行计划:
语法改写的解决方案
DBA或者开发人员通常使用语法改写技术来改进SQL语句,尤其是对于Oracle或者MySQL数据库,但对于MS SQL Server或者IBM Db2 LUW的用户来说语法改写并不容易使用。原因是MS SQL Server和IBM Db2 LUW在它们的SQL优化器中有一个强大的内部改写引擎。这个内部SQL改写引擎会尝试将SQL语法改写为它们的内部规范语法。这意味着,无论您如何改写您的SQL语句,MS SQL Server或者IBM Db2 LUW都会尝试将SQL重新改写回它们内部假定的最优语法。所以如果假定的最优语法不好,就很难调优SQL。因为用户不容易通过简单的SQL改写来影响数据库SQL优化器生成更好的执行计划。
查询提示解决方案
为了解决这个问题,SQL Server为用户提供了查询提示功能,以帮助它的SQL优化器生成更好的执行计划。 它不像SQL改写方法,经验丰富的开发人员可能会说出改写SQL的最终执行计划是什么。查询提示是一个精确的解决方案,它通常应用于整个执行计划中的特定步骤,但对特定步骤的更改将会对整个执行计划的其他步骤产生多米诺效应。因此MS SQL Server必须调整其它步骤以实现用户对SQL语句中查询提示的预期。所以最终的执行计划并不容易被用户预测,尤其是对复杂的SQL语句。
以下由Tosska SQL Tuning Expert生成带提示的SQL比原来的SQL快了4倍左右,耗时0.639秒。
select *
from DEPARTMENT
where exists (select ‘x’
from employee
where emp_id > 2700000
and emp_dept = DPT_ID) OPTION(LOOP JOIN,HASH GROUP)
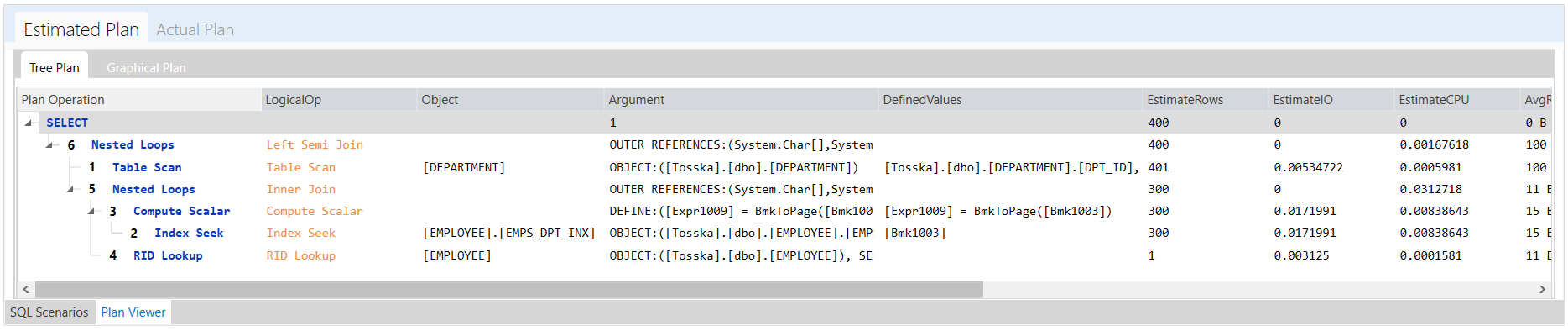
还有一个带提示的SQL,它比原始的SQL快了50倍左右,只需0.055秒。这个执行计划非常接近我上一篇文章中的改写调优。
select *
from DEPARTMENT
where exists (select ‘x’
from employee WITH(INDEX(EMPS_DPT_INX))
where emp_id > 2700000
and emp_dept = DPT_ID)
语法改写加提示的解决方案
对于一些SQL语句,语法改写或者提示方法可能无法单独解决一个复杂的SQL性能问题,有些人可能会想,是否有可能同时改写和应用提示来改进一条SQL语句?是的,这在Tosska SQL Tuning Expert人工智能引擎中是可能的,这种技术可以解决更多的SQL性能问题。稍后我将在我的博客中讨论这项技术。
Tosska SQL Tuning Expert (TSES™) for SQL Server® – Tosska Technologies Limited
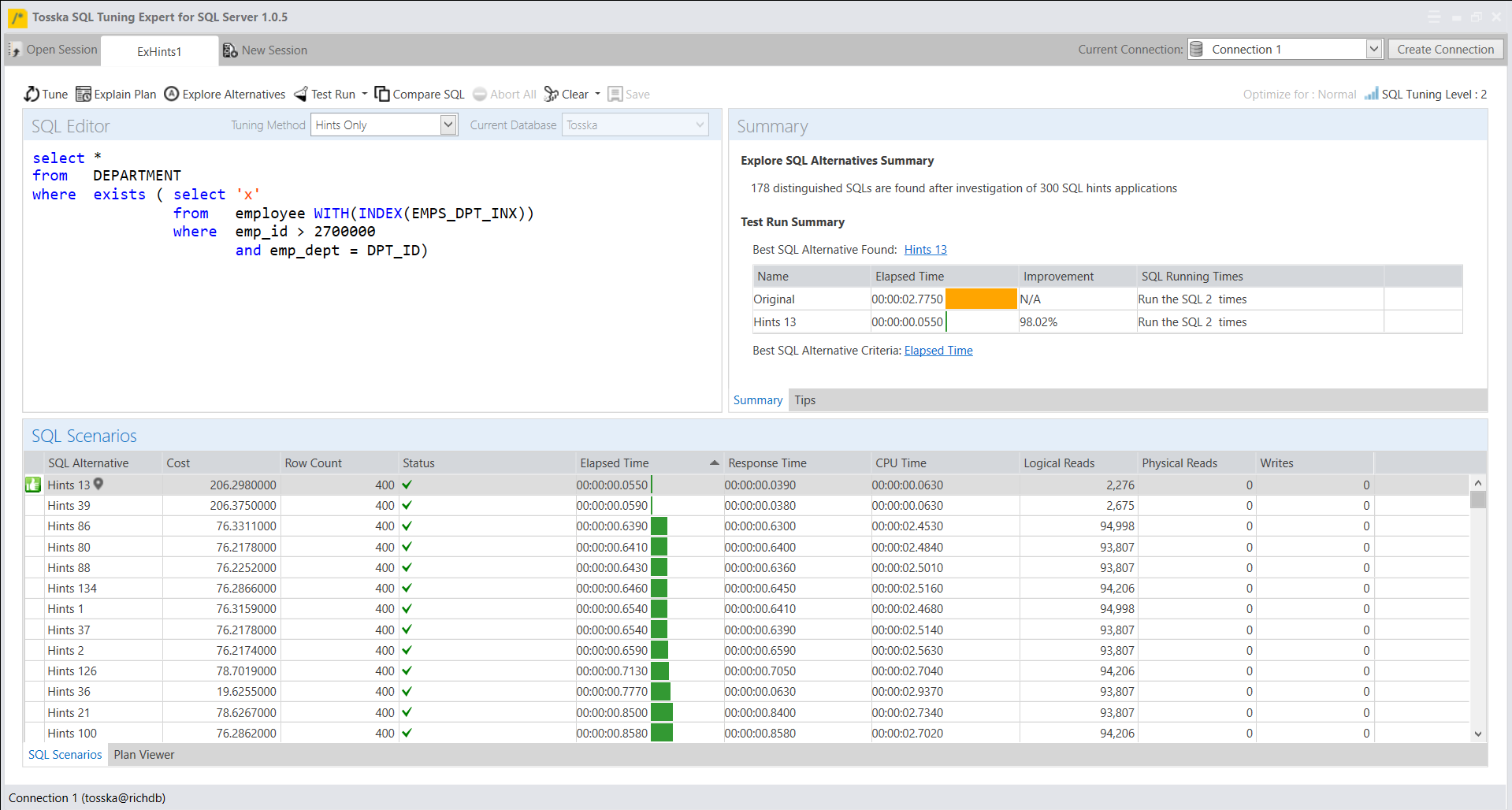
下面显示Tosska SQL Tuning Expert在考察300种加提示的SQL写法后挑选出178条等价SQL,这远远超出了一个专家在10分钟内所能达到的水平。MS SQL Server是市场上对提示注入最敏感的数据库,SQL Server的查询提示通常能够影响SQL优化器生成特定的执行计划,因此MS SQL Server的SQL调优远比其他数据库更具挑战性。

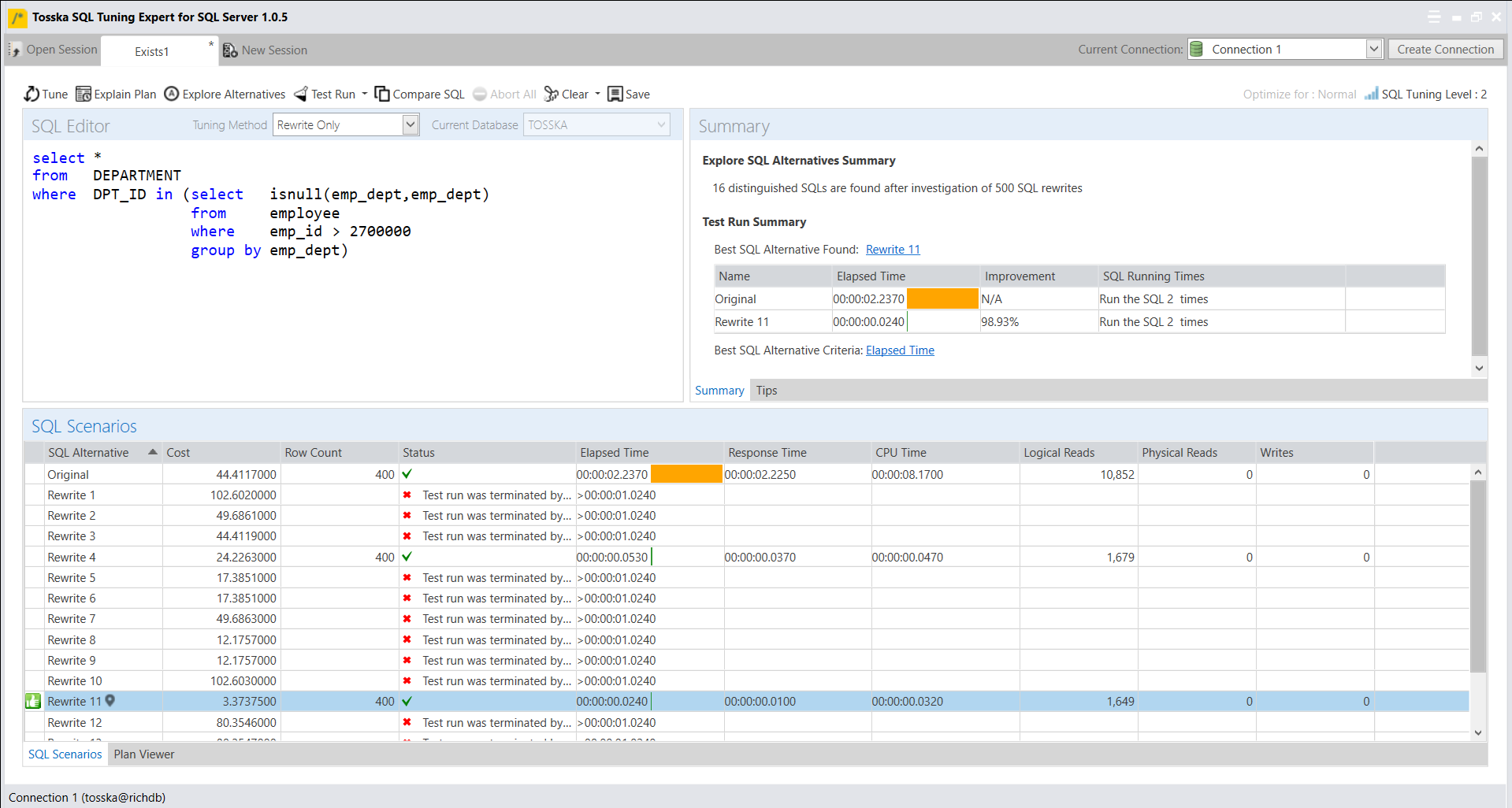
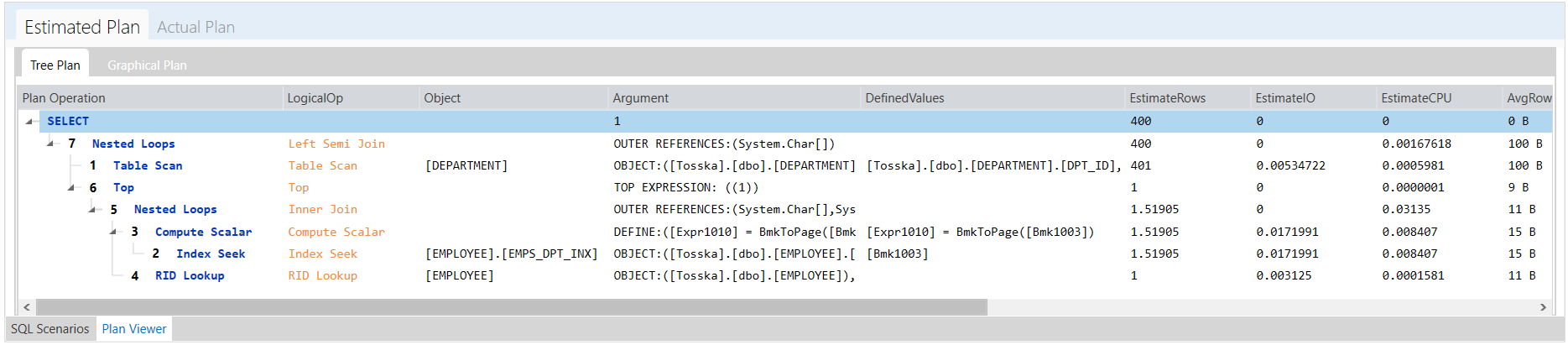
下面示例展示了一个带有Exists子查询的SQL语句。该SQL语句查询DEPARTMENT表中DPT_ID列的值和employee表中emp_dept列的值相等并且employee表中emp_id列的值大于2700000的记录。
SELECT *
FROM DEPARTMENT
where exists (select ‘x’
from employee
where emp_id > 2700000
and emp_dept=DPT_ID)
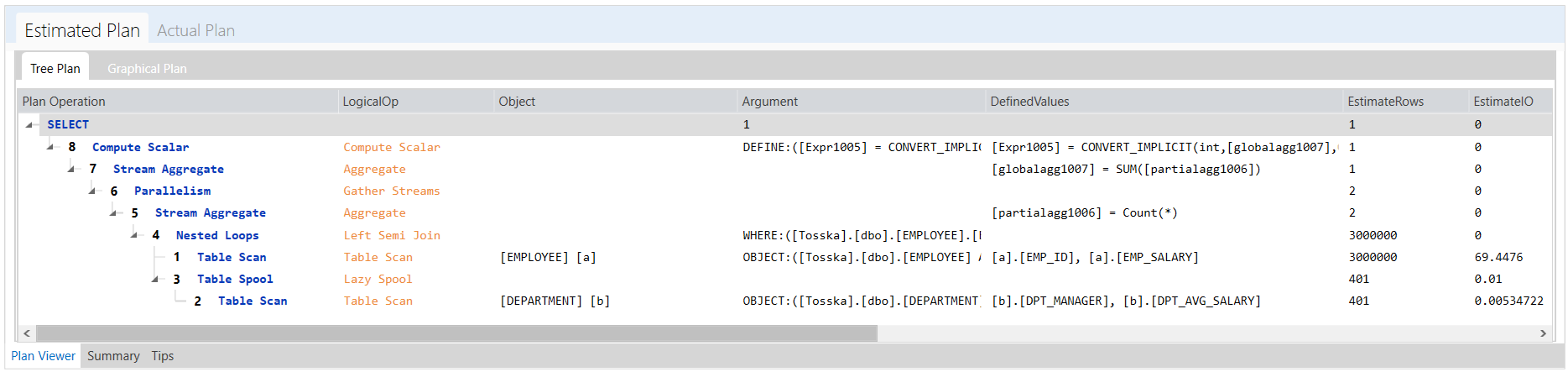
下面是Tosska树结构执行计划,该sql语句执行需要2.23秒才能完成。
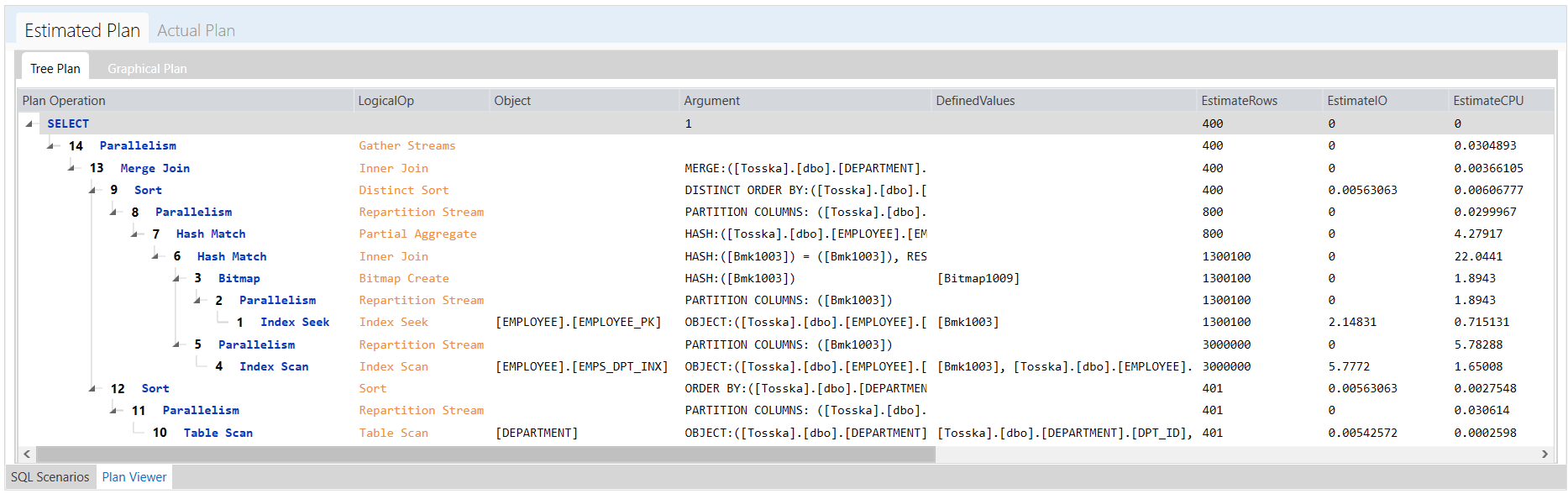
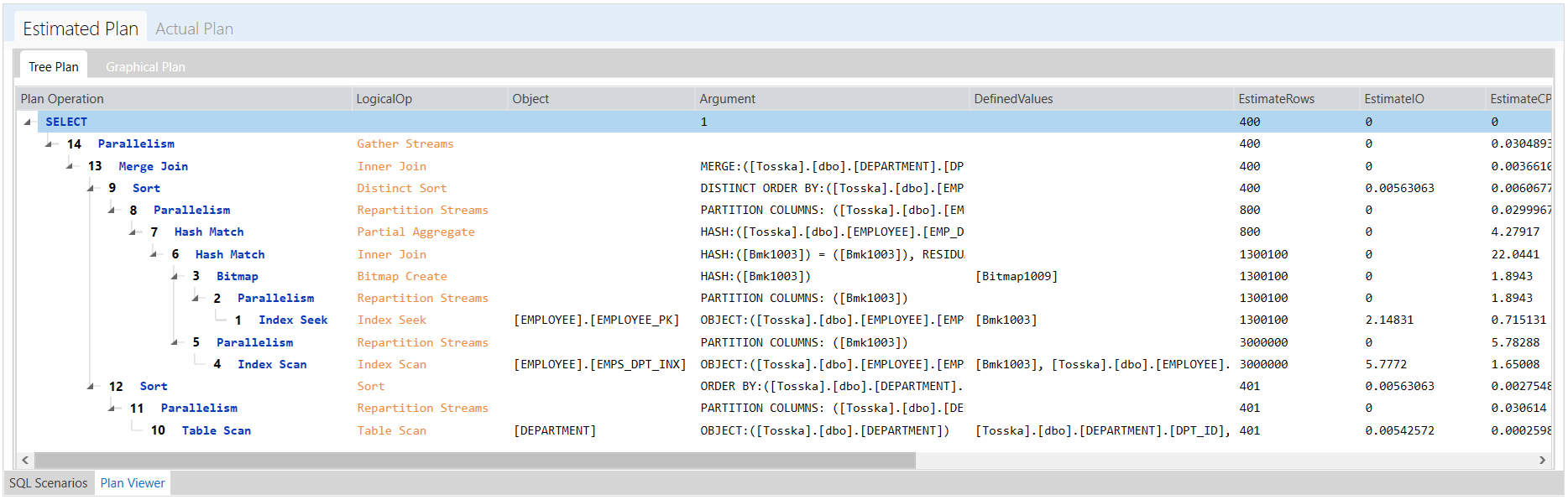
该执行计划显示了从[EMPLOYEE].[EMPLOYEE_PK]到[EMPLOYEE].[EMPS_DPT_INX]的两个哈希匹配,然后合并连接到排序的[DEPARTMENT]表。这个执行计划看起来很合理,但是在第一阶段从[EMPLOYEE]表扫描的记录数太多了,我们可以用比较小的[DEPARTMENT]表去扫描[EMPLOYEE]表来改善这条SQL语句。
下面让我将EXISTS子查询改写为IN子查询,但是执行计划并没有按照预期的改变。
select *
from DEPARTMENT
where DPT_ID in (select emp_dept
from employee
where emp_id > 2700000)
我将进一步的改写SQL,并且添加伪函数“isnull(emp_dept,emp_dept)”到查询列表中,但它不能停止哈希匹配到[EMPLOYEE].[EMPS_DPT_INX]的操作。
select *
from DEPARTMENT
where DPT_ID in (select isnull(emp_dept,emp_dept)
from employee
where emp_id > 2700000)
为了进一步停止“哈希匹配到[EMPLOYEE].[EMPS_DPT_INX]”这一操作,我尝试在子查询中添加“group by emp_dept”伪操作。
select *
from DEPARTMENT
where DPT_ID in (select isnull(emp_dept,emp_dept)
from employee
where emp_id > 2700000)
group by emp_dept)
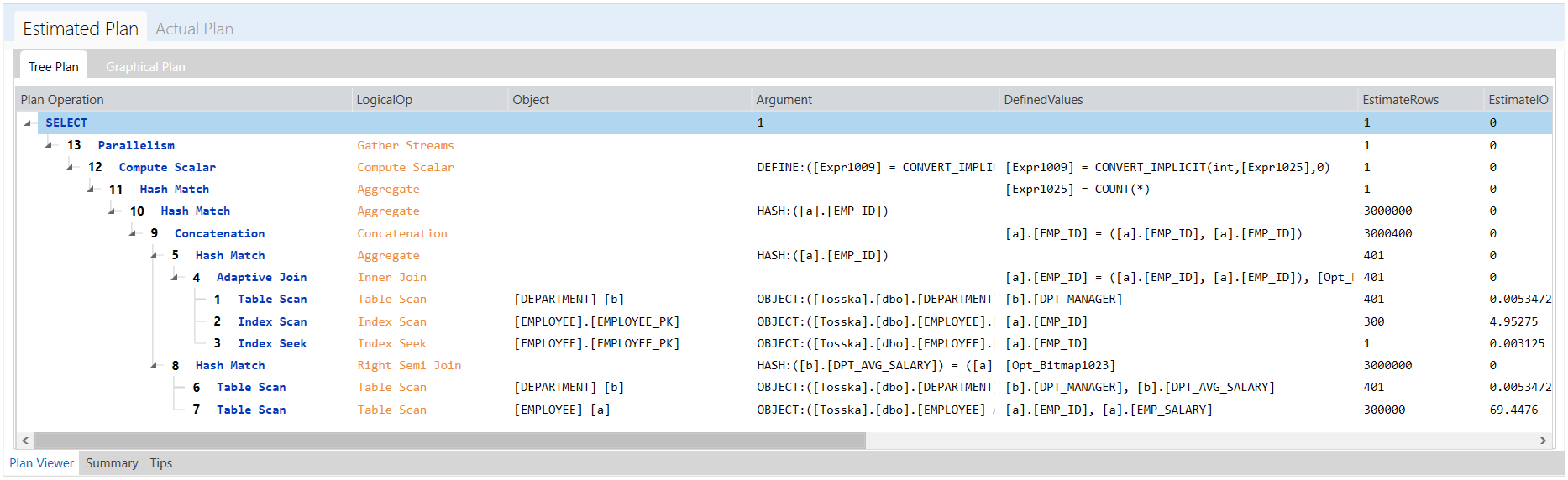
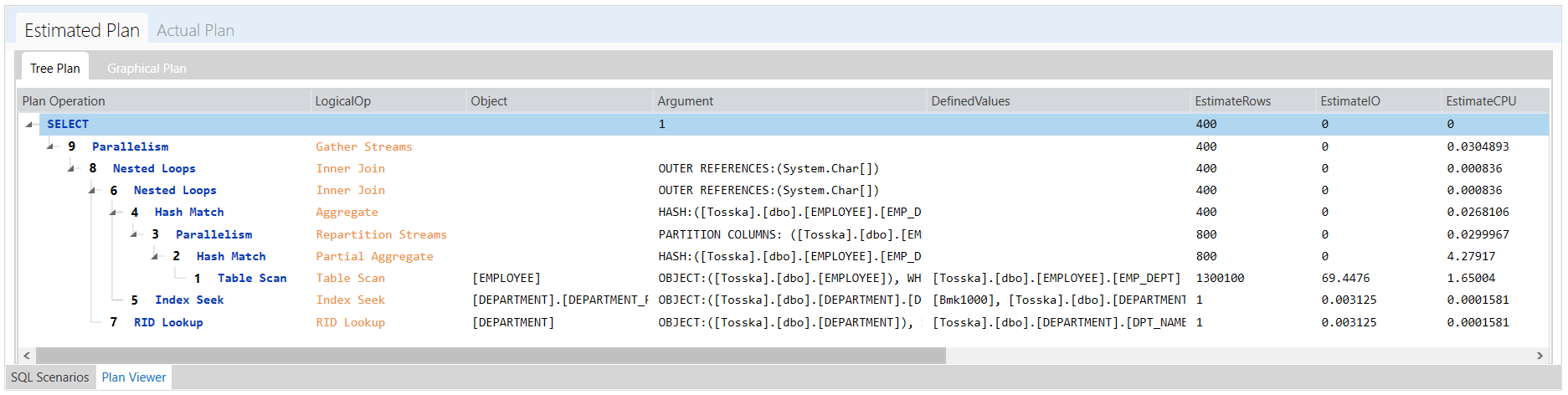
下面是最终改写后的执行计划,SQL Server首先对[DEPARTMENT]进行表扫描和EMPS_DPT_INX索引从[EMPLOYEE]中寻找RID的嵌套循环操作,因此[DEPARTMENT]表中的每条记录最多匹配一次[EMPLOYEE]。现在的执行速度是0.024秒,比原来的SQL快很多。
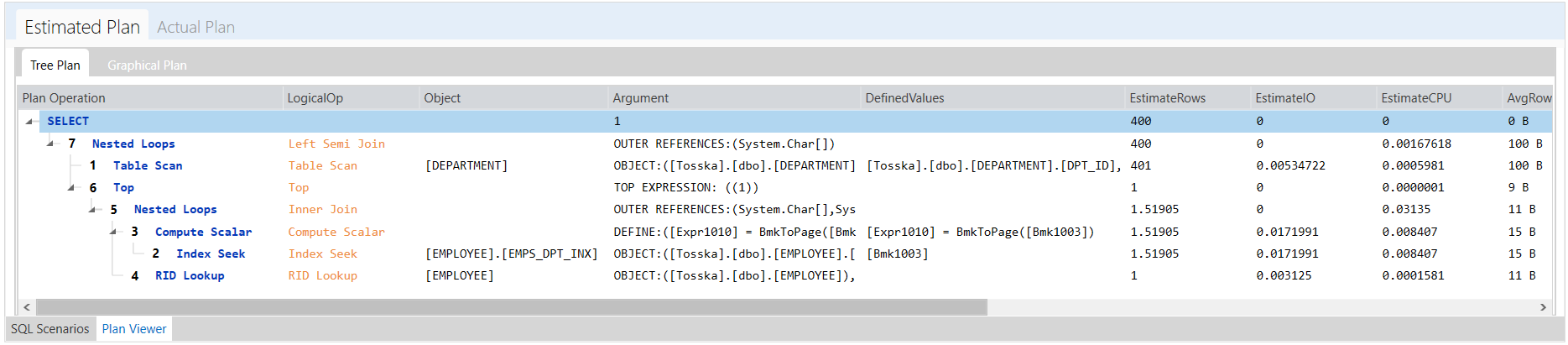
尽管改写的步骤有点复杂,但它可以由Tosska SQL Tuning Expert for SQL Server自动实现,并且它比原始SQL快了90多倍。
Tosska SQL Tuning Expert (TSES™) for SQL Server® – Tosska Technologies Limited